query3는 숫자, 문자열 모두 포함하므로 반환형이 명확하지 않다. 따라서 반환 클레스를 명시하지 않는다.
즉, TypedQuery가 아닌 Query이다.
TypedQuery<Member> query1 = em.createQuery("select m from Member m", Member.class);
TypedQuery<String> query2 = em.createQuery("select m.userName from Member m", String.class);
Query query3 = em.createQuery("select m.userName, m.age from Member m");
결과 조회 API
query.getResultList() : 결과가 하나 이상일 때, 리스트 반환
결과가 없으면 빈 리스트 반환
query.getSingleResult() : 결과가 정확히 하나일 때
결과가 없으면 : javax.persistence.NoResultException
둘 이상이면 : javax.persistence.NonUniqueResultException
Member member = new Member();
member.setUserName("member1");
member.setAge(10);
em.persist(member);
TypedQuery<Member> query1 = em.createQuery("select m from Member m", Member.class);
List<Member> resultList = query1.getResultList();
for (Member member1 : resultList) {
System.out.println("member1.getUserName() = " + member1.getUserName());
}
Member singleResult = query1.getSingleResult();
System.out.println("singleResult.getUserName() = " + singleResult.getUserName());
EnttiyManager.createQuery() 를 그냥 반환하면 TypedQuery 혹은 Query가 나오기 때문에 이 쿼리 타입들에서 한번더 값을 조회 해야 한다.
다중 객체를 조회하는 getResultList(), 단일 객체를 조회하는 getSingleResult()를 사용하면 원하는 엔티티의 타입을 얻을 수 있다.
null이 나와도 예외없이 반환하는 getResultList와는 달리, getSingleResult는 값이 null이라면 NoResultException이 발생하고, 둘 이상이라면 NonUniqueResultException이 발생한다.
Spring Data JPA에서는 단일 반환일 때 Optional을 반환하여 예외가 터지지 않게 한다.
파라미터 바인딩 - 이름 기준, 위치 기준
JPQL에 원하는 파라미터를 넣을때에는 이름을 기준으로 넣는것과, 순서를 기준으로 넣는방법이 있다.
이름기준
where문에 =: 파라미터명 을 추가한다.
이후 setParameter에서 기존에 입력한 파라미터명과, 실제 데이터를 넣는다.
Member singleResult = em.createQuery("select m from Member m where m.userName = :username", Member.class)
.setParameter("username", "member1")
.getSingleResult();
System.out.println("singleResult = " + singleResult.getUserName());
순서기준 (비추천, 순서가 밀릴 위험)
where 절의 = : 파라미터 대신 = ?숫자 로 변경하면 된다. 밑의 파라미터도 문자열대신 숫자로 변경
다만, 중간에 값이 추가되면 값이 그대로 밀릴 수 있으므로 권장하지 않는다.
Member singleResult = em.createQuery("select m from Member m where m.userName = ?1", Member.class)
.setParameter(1, "member1")
.getSingleResult();
프로젝션(SELECT)
SELECT 절에 조회할 대상을 지정하는 것
프로젝션 대상 : 엔티티, 임베디드 타입, 스칼라 타입(숫자, 문자 등 기본 데이터 타입)
SELECT m FROM Member m -> 엔티티 프로젝션
SELECT m.team FROM Member m -> 엔티티 프로젝션
SELECT m.address From Member m -> 임베디드 타입 프로젝션
SELECT m.username, m.age FROM Member m -> 스칼라 타입 프로젝션
관계형 데이터베이스의 경우에는 스칼라 타입만 조회가 가능한데, JPQL의 경우 엔티티, 임베디드 타입도 조회 가능하다.
스칼라 타입이란, 우리가 일반적으로 DB에서 데이터를 조회할 때 반환되는 기본형 값들을 말한다.
엔티티 프로젝션
엔티티 프로젝션을 하면 10개든 20개든 엔티티들이 전부 영속성 컨텍스트에서 관리된다. 다음과 같이 age가 10인 member를 영속한 후, 쿼리를 날리고 캐시를 비웠다.
Member member = new Member();
member.setUserName("member1");
member.setAge(10);
em.persist(member);
em.flush();
em.clear();
List<Member> resultList = em.createQuery("select m from Member m", Member.class)
.getResultList();
Member findMember = resultList.get(0);
findMember.setAge(20);
엔티티 프로젝션으로 member를 조회하면, 수정을 했을 때 JPA에서는 변경을 감지하고 update 쿼리를 실행한다
Hibernate:
/* update
for com.example.jpa.jpql.Member */update member
set
age=?,
team_id=?,
user_name=?
where
id=?
엔티티 프로젝션(참조 엔티티의 경우)
참조 엔티티를 조회할 때에는 당연하지만 반환 클레스도 참조 클레스로 변경해야한다.
첫번째 방식은 join 유무가 한눈에 파악하기 어려우므로
두번째 방식처럼 명시적으로 join을 표시해주는것이 좋다.
List<Team> worstResult = em.createQuery("select m.team from Member m", Team.class)
.getResultList();
List<Team> bestResult = em.createQuery("select t from Member m join m.team t", Team.class)
.getResultList();
참조 엔티티를 반환형으로 지정했지만 쿼리 자체는 멤버에서 찾으므로 join 쿼리가 나간다.
Hibernate:
/* select
m.team
from
Member m */ select
t1_0.id,
t1_0.name
from
member m1_0
join
team t1_0
on t1_0.id=m1_0.team_id
임베디드 타입 프로젝션
임베디드 타입은 엔티티가 아닌 값이기 때문에 select의 주체가 되지 못한다. 즉, Entity.EmbeddedType 으로 조회해야 한다.
그렇기에 두번째 코드는 컴파일 에러가 나타난다.
스칼라 타입 프로젝션
반환타입을 제거하면 된다.
List resultList = em.createQuery("select m.userName, m.age from Member m")
.getResultList();
이 스칼라 타입은 어떻게 조회될까?
SELECT m.username, m.age FROM Member m
1. Query 타입으로 조회
아래 코드는 반환타입 따로 지정하지 않아 반환타입 없이 그냥 List로만 반환되지만,
실제로는 내부적으로 Object[] 형식을 취한다고 한다.
실제로 조회해보면 다음과 같다.
Member member = new Member();
member.setUserName("member1");
member.setAge(10);
em.persist(member);
List resultList = em.createQuery("select m.userName, m.age from Member m")
.getResultList();
for (Object o : resultList) {
log.info("o = {}",o);
log.info("o.getClass = {}",o.getClass());
}
class [Ljava.lang.Object; 이 Object[] 를 의미한다.
o = [member1, 10]
o.getClass = class [Ljava.lang.Object;
2. Object[] 타입으로 조회
Member member = new Member();
member.setUserName("member1");
member.setAge(10);
em.persist(member);
List<Object[]> result = em.createQuery("select m.userName, m.age from Member m")
.getResultList();
for (Object[] objects : result) {
log.info("objects={}", Arrays.toString(objects));
}
3. new 명령어로 조회 - 단순 값을 DTO로 바로 조회 - SELECT new jpabook.jpql.UserDTO(m.username, m.age) FROM Member m - 패키지명을 포함한 전체 클래스명 입력 - 순서와 타입이 일치하는 생성자 필요
memberDTO 추가, toString을 오버라이딩 한다.
public class MemberDTO {
private String username;
private int age;
public MemberDTO(String username, int age) {
this.username = username;
this.age = age;
}
@Override
public String toString() {
return "MemberDTO{" +
"username='" + username + '\'' +
", age=" + age +
'}';
}
}
이후 조회문에서 DTO의 패키지 주소를 전부 적어서 mebmerDTO 객체를 추가한다.
Member member = new Member();
member.setUserName("member1");
member.setAge(10);
em.persist(member);
List<MemberDTO> resultList = em.createQuery("select new com.example.jpa.jpql.MemberDTO(m.userName, m.age) from Member m", MemberDTO.class)
.getResultList();
for (MemberDTO memberDTO : resultList) {
log.info(memberDTO.toString());
}
다음처럼 DTO에 감싸져서 온다.
MemberDTO{username='member1', age=10}
마지막 방법이 제일 좋아보이지만 DTO로 조회하려면 패키지명을 전부 적어야하는 불편함이 있다. 문자열로 조회를 하기때문에 오타를 찾기도 어렵다.
하나는 int, Integer, String 처럼 단순히 값으로 사용하는 자바 기본타입이나 객체인 값 타입이다.
값 타입은 기본값 타입, 임베디드 타입, 컬렉션 값 타입으로 나뉜다.
기본값 타입은 자바 기본타입, 래퍼클래스, String을 포함 하는 값 타입이고
임베디드 타입은 복합 값 타입 이라고 하며, 사용자가 직접 정의하는 값 타입이며
컬렉션 값 타입은 기본값, 임베디드 타입을 컬렉션으로 묶은것이 컬렉션 값 타입이다.
2) 값 타입 분류
1 - 기본값 타입
예 : String name, int age
생명주기를 엔티티에 의존
예 : 회원을 삭제하면 이름, 나이 필드도 제거됨
값 타입은 공유하면 x
예: 회원 이름 변경 시 다른 회원의 이름도 함께 변경되면 안됨
참고 : 자바의 기본 타입은 절대 공유X
- int double 같은 기본 타입은 절대 공유 X
- 기본 타입은 항상 값을 복사함
- Integer 같은 래퍼 클래스나 String 같은 특수한 클래스는 공유 가능하능한 객체이지만 변경 X
int, double같은 기본 타입은 절대 공유되지 않는다. 그렇기에 값타입으로 썼을 때 안전하다.
@Test
void valueTest() {
int a = 10;
int b = a;
a = 20;
System.out.println("a = " + a);
System.out.println("b = " + b);
}
------------------------------------
a = 20
b = 10
a와 b는 저장공간을 따로 가지고 있어서
b의 값은 a가 10일때 초기화되고 a는 20으로 할당되어
a = 20 , b = 10이 된다.
이렇듯 기본형은 값이 공유되지 않는다.
그래서 부수효과가 일어나지 않는다.
래퍼 클래스같은 경우, 참조값을 공유하지만, 변경이 불가능하기때문에 안전하다.
2 - 임베디드 타입
새로운 값 타입을 직접 정의할 수 있음
JPA는 임베디드 타입(embedded type) 이라고 함
주로 기본 값 타입을 모아 만들어서 복합 값 타입이라고도 함
int, String과 같은 값 타입
@Embeddable : 값 타입을 정의하는 곳에 표시
@Embedded : 값 타입을 사용하는 곳에 표시
기본 생성자 필수
2-1 임베디드 타입의 장점
재사용
높은 응집도
Period.isWork() 처럼 해당 값 타입만 사용하는 의미 있는 메서드를 만들 수 있음
임베디드 타입을 포함한 모든 값 타입은, 값 타입을 소유한 엔티티에 생명주기를 의존함 (값 타입이기 때문에)
임베디드 타입은 객체이기 때문에 데이터 뿐만 아니라 메서드까지 가지고 있기 때문에 거기서 오는 이득이 많다.
임베디드 타입 자체에는 @Embeddable을, 임베디드 타입을 사용할 엔티티의 속성에는 @Embedded를 붙인다.
@Entity
@Getter
@Setter
public class Member {
@Id
@GeneratedValue
@Column(name = "member_id")
private Long id;
@Column(name = "username")
private String username;
@Embedded
private Period workPeriod;
@Embedded
private Address homeAddress;
@Embeddable
@Getter
@Setter
@NoArgsConstructor
public class Address {
private String city;
private String street;
private String zipcode;
public Address(String city, String street, String zipcode) {
this.city = city;
this.street = street;
this.zipcode = zipcode;
}
}
@Embeddable
@Setter
@Getter
@NoArgsConstructor
public class Period {
private LocalDateTime startDate;
private LocalDateTime endDate;
public Period(LocalDateTime startDate, LocalDateTime endDate) {
this.startDate = startDate;
this.endDate = endDate;
}
}
이러한 값 타입은 불변객체여야 하기 때문에 Setter대신 생성자를 통해 새로운 값을 만들어야 한다.
int 같은 기본형 타입은 애초에 참조가 존재하지 않아서 늘 새로운 값이 저장되므로 중간에 어떠한 값이 바뀌더라도 그것을 이용한 다른 값들이 변경되지 않지만,
임베디드 타입은 객체이므로 참조를 통해 값을 가져오기 때문에 중간에 값이 변경되면 그것과 연관되는 다른값들도 부수효과가 일어나기 때문에, 이러한 값타입들은 불변객체여야 한다.
Member member =new Member();
member.setHomeAddress(new Address("city","street","1000"));
member.setWorkPeriod(new Period(LocalDateTime.now(),LocalDateTime.now()));
em.persist(member);
이처럼 따로 테이블이 생성되지 않고 member의 컬럼으로써 동작한다.
Hibernate:
create table member (
end_date datetime(6),
member_id bigint not null,
start_date datetime(6),
team_id bigint,
city varchar(255),
street varchar(255),
username varchar(255),
zipcode varchar(255),
primary key (member_id)
) engine=InnoDB
Hibernate:
/* insert for
com.example.jpa.domain.Member */insert
into
member (city,street,zipcode,username,end_date,start_date,member_id)
values
(?,?,?,?,?,?,?)
2-2 임베디드 타입과 테이블 매핑
임베디드 타입은 엔티티의 값일 뿐이다.
임베디드 타입을 사용하기 전과 후에 매핑하는 테이블은 같다.
객체와 테이블을 아주 세밀하게(find-grained) 매핑하는 것이 가능
잘 설계한 ORM 애플리케이션은 매핑한 테이블의 수보다 클래스의 수가 더 많음
2-3 @AttributeOverride
@AttributeOverride는 임베디드타입의 속성을 재정의하며, 엔티티 내에서 같은 임베디드 타입을 쓸 때 컬럼이 중복되지 않게 컬럼명을 변경할 수 있다.
@Entity
@Getter
@Setter
public class Member {
@Id
@GeneratedValue
@Column(name = "member_id")
private Long id;
@Column(name = "username")
private String username;
@Embedded
private Period workPeriod;
@Embedded
private Address homeAddress;
@Embedded
@AttributeOverrides({
@AttributeOverride(name="city",
column=@Column(name = "work_city")),
@AttributeOverride(name="street",
column=@Column(name = "work_street")),
@AttributeOverride(name="zipcode",
column=@Column(name = "work_zipcode"))
})
private Address workAddress;
}
이렇게 임베디드 타입인 homeAddress의 컬럼과, workAddress의 컬럼이 구분되어 쿼리가 작성된다.
Hibernate:
/* insert for
com.example.jpa.domain.Member */insert
into
member (city,street,zipc5de,username,work_city,work_street,work_zipcode,end_date,start_date,member_id)
values
(?,?,?,?,?,?,?,?,?,?)
참고 : 임베디드 타입의 값이 null 이면, 매핑한 컬럼 값은 null이 된다.
3) 값 타입과 불변 객체
1 - 값 타입 공유 참조
임베디드 타입은 여러 엔티티에서 동시에 같은 인스턴스를 참조할 수 있다.
Address address = new Address("city", "street", "1000");
Member member1 =new Member();
member1.setUsername("member1");
member1.setHomeAddress(address);
em.persist(member1);
Member member2 =new Member();
member2.setUsername("member2");
member2.setHomeAddress(address);
em.persist(member2);
member1.getHomeAddress().setCity("newCity");
member1의 Address의 값을 변경했으나, address라는 참조를 member2도 같이 사용하므로 값이 공유된다.
결론적으로 같은 임베디드 타입 값을 공유하였기 때문에 사이드 이팩트가 난 것이다.
Hibernate:
/* update
for com.example.jpa.domain.Member */update member
set
city=?,
street=?,
zipc5de=?,
username=?,
end_date=?,
start_date=?
where
member_id=?
Hibernate:
/* update
for com.example.jpa.domain.Member */update member
set
city=?,
street=?,
zipc5de=?,
username=?,
end_date=?,
start_date=?
where
member_id=?
그렇기에 임베디드 타입 같은 값 타입을 여러 엔티티에서 공유하면 굉장히 위험하다. 만약 이렇게 2개가 동시에 수정되는것을 의도하고자 한다면 임베디드 타입이 아닌 엔티티로 승격시켜야 한다.
2 - 값 타입 복사
위처럼 같은 실제 인스턴스를 공유하는것은 위험하기 때문에
같은 값을 넣으려면 새로운 인스턴스를 만들어서 기존의 값을 복사해야 한다.
Address address1 = new Address("city", "street", "1000");
Member member1 =new Member();
member1.setUsername("member1");
member1.setHomeAddress(address1);
em.persist(member1);
Address address2 = new Address(address1.getCity(), address1.getStreet(), address1.getZipcode());
Member member2 =new Member();
member2.setUsername("member2");
member2.setHomeAddress(address2);
em.persist(member2);
member1.getHomeAddress().setCity("newCity");
3 - 객체 타입의 한계
항상 값을 복사해서 사용하면 공유 참조로 인해 발생하는 부작용을 피할 수 있다.
문제는 임베디드 타입처럼 직접 정의한 값 타입은 자바의 기본 타입이 아니라 객체 타입이다.
자바 기본 타입에 값을 대입하면 값을 복사한다.
객체 타입은 참조 값을 직접 대입하는 것을 막을 방법이 없다.
객체의 공유 참조는 피할 수 없다.
기본 타입
int a = 10;
int b= a; // 기본 타입은 값을 복사
b = 4;
기본타입은 = 을 하면 값이 복사가 된다. 그래서 b의 값을 4로 변경하여도 a의 값은 유지된다.
객체 타입
Address a = new Address("old");
Address b = a; // 객체 타입은 참조를 전달
b. setCity("New")
여기서는 a,b 모두 같은 인스턴스를 가르키기 때문에 값이 변경되는 순간 a의 값도 변경된다.
4 - 불변 객체
객체 타입을 수정할 수 없게 만들면 부작용을 원천 차단
값 타입은 불변 객체(immutable object)로 설계해야 함
불변 객체 : 생성 시점 이후 절대 값을 변경할 수 없는 객체
생성자로만 값을 설정하고 수정자(Setter)를 만들지 않으면 됨
참고 : Integer, String은 자바가 제공하는 대표적인 불변 객체
값을 변경하려면
address 자체를 통으로 새로 만들고, homeAddress 자체를 newAddress로 변경한다.
ddress address1 = new Address("city", "street", "1000");
Member member1 =new Member();
member1.setUsername("member1");
member1.setHomeAddress(address1);
em.persist(member1);
Address newAddress = new Address("newCity", address1.getStreet(), address1.getZipcode());
member1.setHomeAddress(newAddress);
Hibernate:
create table address (
member_id bigint not null,
city varchar(255),
street varchar(255),
zipcode varchar(255)
) engine=InnoDB
다음과 같이 테스트 코드를 작성한다.
값 타입 저장
Member member = new Member();
member.setUsername("member1");
member.setHomeAddress(new Address("homeCity","street","1000"));
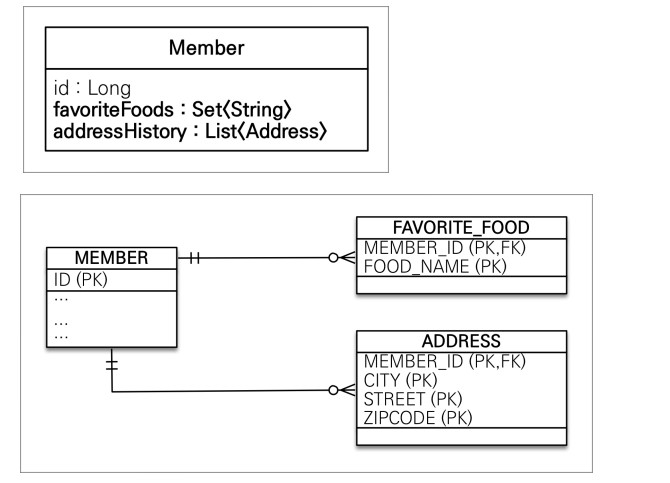
member.getFavoriteFoods().add("치킨");
member.getFavoriteFoods().add("족발");
member.getFavoriteFoods().add("피자");
member.getAddressesHistory().add(new Address("oldCity1","street","1000"));
member.getAddressesHistory().add(new Address("oldCity2","street","1000"));
em.persist(member);
흥미로운 점은 값 타입 컬렉션을 따로 영속하지 않아도 member만 영속하니까 다른 테이블들도 저장이 되었다. 즉 라이프사이클이 다른 테이블임에도 불구하고 member와 같이 돌아가고 있는것이다.
값 타입 컬렉션도 본인 스스로 라이프 사이클이 없다. 값 타입 컬렉션도 결국은 값 타입이기 때문에 라이프 사이클을 엔티티에 의존한다.
또한 이런 값 타입 컬렉션은 기본이 지연로딩이라서 실제 데이터를 요청하기 전 까지는 데이터를 부르지 않는다.
참고로 컬렉션들은 대부분 대상을 찾을 때 equals 를 사용한다. 그래서 완전히 똑같은 equals 대상을 넣어주면 해당 값을 지울 수 있다. 그렇기 때문에 값 타입은 equals와 hashcode를 구현해 놓아야 한다.
값 타입 리스트 수정
Member member = new Member();
member.setUsername("member1");
member.getAddressesHistory().add(new Address("oldCity1","street","1000"));
member.getAddressesHistory().add(new Address("oldCity2","street","1000"));
em.persist(member);
em.flush();
em.clear();
System.out.println("========================================");
Member findMember = em.find(Member.class, member.getId());
findMember.getAddressesHistory().remove(new Address("oldCity1","street", "1000"));
-------------------------------------------------------------------------------------
HashSet(FavoriteFoods) 경우 수정 코드 :
findMember.getFavoriteFoods().remove("치킨");
findMember.getFavoriteFoods().add("한식");
쿼리를 보면 해당 멤버에 소속된 addressHistory의 값 전체를 다 지웠다. 그리고 이상하게도 insert문이 2번 나왔다.
Hibernate:
select
m1_0.member_id,
m1_0.city,
m1_0.street,
m1_0.zipcode,
m1_0.username
from
member m1_0
where
m1_0.member_id=?
Hibernate:
select
a1_0.member_id,
a1_0.city,
a1_0.street,
a1_0.zipcode
from
address a1_0
where
a1_0.member_id=?
Hibernate:
/* one-shot delete for com.example.jpa.domain.Member.addressesHistory */delete
from
address
where
member_id=?
Hibernate:
/* insert for
com.example.jpa.domain.Member.addressesHistory */insert
into
address (member_id,city,street,zipcode)
values
(?,?,?,?)
Hibernate:
/* insert for
com.example.jpa.domain.Member.addressesHistory */insert
into
address (member_id,city,street,zipcode)
values
(?,?,?,?)
1 - 값 타입 컬렉션의 제약사항
값 타입은 엔티티와 다르게 식별자 개념이 없다.
값은 변경하면 추적이 어렵다.
값 타입 컬렉션에 변경 사항이 발생하면, 주인 엔티티와 연관된 데이터를 모두 삭제하고, 값 타입 컬렉션에 있는 현재 값을 모두 다시 저장한다.
값 타입 컬렉션을 매핑하는 테이블은 모든 컬럼을 묶어서 기본키를 구성해야 함: null 입력x, 중복 저장 x
값 타입 컬렉션에서 수정을 하려면 결국 해당 id에 대한 값을 모두 지우고 다시 리스트에 있는 값을 저장하기 때문에 효율적이지 않다.
결론적으로 정말 단순한 것 외에는 실무에서 그대로 사용하기는 어렵다
2 - 값 타입 컬렉션 대안
실무에서는 상황에 따라 값 타입 컬렉션 대신에 일대 다 관계를 고려
일대다 관계를 위한 엔티티를 만들고, 여기에서 값 타입을 사용
영속성 전이(CASCADE) + 고아 객체 제거를 사용해서 값 타입 컬렉션처럼 사용
임베디드 타입 Address를 Entity로 승격
@Entity
@Getter
@Setter
@Table(name = "address")
@NoArgsConstructor
public class AddressEntity {
@Id @GeneratedValue
private Long id;
private Address address;
public AddressEntity(Address address) {
this.address = address;
}
public AddressEntity(String city, String street, String number) {
this.address = new Address(city,street,number);
}
}
addressHistory에 @CollectionTable 대신 @OneToMany(cascade = CascadeType.ALL, orphanRemoval = true) 설정
@Entity
@Getter
@Setter
public class Member {
@Id
@GeneratedValue
@Column(name = "member_id")
private Long id;
@Column(name = "username")
private String username;
@Embedded
private Address homeAddress;
@ElementCollection
@CollectionTable(name = "favorite_food", joinColumns =
@JoinColumn(name = "member_id"))
@Column(name = "food_name")
private Set<String> favoriteFoods = new HashSet<>();
@OneToMany(cascade = CascadeType.ALL, orphanRemoval = true)
@JoinColumn(name = "member_id")
private List<AddressEntity> addressesHistory = new ArrayList<>();
}
JPA에서 지연 로딩(Lazy Loading)은 연관된 엔티티나 컬렉션을 즉시 로딩하지 않는 전략을 의미한다. 대신, 실제로 해당 데이터에 접근이 필요할 때 (예: 프로퍼티의 값을 가져오는 경우) 데이터베이스에서 해당 데이터를 로드한다.
연관관계에 FetchType.LAZY속성을 추가
package com.example.jpa.domain;
import jakarta.persistence.*;
import lombok.Getter;
import lombok.Setter;
import lombok.extern.java.Log;
import java.util.ArrayList;
import java.util.List;
@Entity
@Getter
@Setter
public class Member extends BaseEntity {
@Id
@GeneratedValue
@Column(name = "member_id")
private Long id;
@Column(name = "username")
private String username;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "team_id")
private Team team;
}
테스트 코드로 Team의 클래스명과, 쿼리를 확인해 보면
Team team = new Team();
team.setName("teamA");
em.persist(team);
Member member1 = new Member();
member1.setUsername("member1");
member1.setTeam(team);
em.persist(member1);
em.flush();
em.clear();
Member member = em.find(Member.class, member1.getId());
System.out.println("member.getTeam().getClass() = " + member.getTeam().getClass());
System.out.println("============================================================");
member.getTeam().getName();
System.out.println("============================================================");
Member 엔티티는 Team을 Join 하지 않고 조회했다가,
실제 Team의 데이터를 조회할 때 조회 쿼리가 나가는것을 알 수 있다.
클래스도 확인해보면 실제 객체가 아닌 프록시 객체를 반환한다.
Hibernate:
select
m1_0.member_id,
m1_0.created_by,
m1_0.created_date,
m1_0.last_modified_by,
m1_0.last_modified_date,
m1_0.team_id,
m1_0.username
from
member m1_0
where
m1_0.member_id=?
member.getTeam().getClass() = class com.example.jpa.domain.Team$HibernateProxy$k43PADH3
============================================================
Hibernate:
select
t1_0.team_id,
t1_0.created_by,
t1_0.created_date,
t1_0.last_modified_by,
t1_0.last_modified_date,
t1_0.name
from
team t1_0
where
t1_0.team_id=?
============================================================
비즈니스 로직 상 대부분 메인 엔티티만 사용하고 참조 엔티티는 많이 쓰지 않을때 쓰는게 좋다. 라고 하지만
실무에서는 대부분 FetchType.LAZY 만 쓰인다고 한다.
정리
모든 연관관계에 지연 로딩을 사용하라
실무에서 즉시 로딩을 사용하지 마라
JPQL fetch 조인이나, 엔티티 그래프 기능을 사용하라
즉시 로딩은 상상하지 못한 쿼리가 나간다.
2. 즉시로딩
지연로딩은 조회 시 가짜 프록시 객체를 만들어 조회하지만
즉시 로딩은 모든것에 Join을 걸고 조회한다
이전 엔티티 코드에서 fetchType.LAZY -> fetchType.EAGER 로 변경해 준 후 동일한 테스트코드를 실행하면
지연로딩과는 다르게 최초 조회시 모든 데이터를 불러오고,
구분선(===...)사이에는 아무것도 조회하지 않는것을 알 수 있다.
데이터를 모두 가지고 오기 때문에 프록시 객체가 아닌 실제 객체를 반환한다.
Hibernate:
select
m1_0.member_id,
m1_0.created_by,
m1_0.created_date,
m1_0.last_modified_by,
m1_0.last_modified_date,
t1_0.team_id,
t1_0.created_by,
t1_0.created_date,
t1_0.last_modified_by,
t1_0.last_modified_date,
t1_0.name,
m1_0.username
from
member m1_0
left join
team t1_0
on t1_0.team_id=m1_0.team_id
where
m1_0.member_id=?
member.getTeam().getClass() = class com.example.jpa.domain.Team
============================================================
============================================================
엔티티와 참조 엔티티가 대부분 같이 사용된다고 한다면 즉시 로딩을 사용한다고 한다.
주의점
데이터베이스 입장에서 한두개 정도는 조인이라고 해서 크게 느리진 않다. 하지만 만약에 수십개라면 완전 다른 차원의 이야기다.
다 즉시로딩으로 10개씩 되어있다고 생각해보자 뭐 하나 할때마다 전부 조인되서 나간다.
그래서 실무에서 테이블이 복잡하게 얽혀있을 때에는 전부 지연 로딩 으로 설정해야 한다.
예를들어 JPQL로 테스트 코드를 작성하면
Team team = new Team();
team.setName("teamA");
em.persist(team);
Member member1 = new Member();
member1.setUsername("member1");
member1.setTeam(team);
em.persist(member1);
em.flush();
em.clear();
List<Member> members = em.createQuery("select m from Member m", Member.class).getResultList();
처음에는 엔티티 객체에 대한 쿼리가 나오고, 그 후에 참조 객체에 대해서 한번 더 조회 쿼리가 나온다. 그렇기에, 조회하려는 엔티티 객체가 10개 라면, 엔티티 쿼리 1개 + 참조 엔티티 쿼리 10개 의 쿼리가 출력된다.
em.find같은 것들은 JPA가 내부적으로 최적화를 해 주지만 JPQL은 쿼리 그대로 나가기 때문이다.
Hibernate:
/* select
m
from
Member m */ select
m1_0.member_id,
m1_0.created_by,
m1_0.created_date,
m1_0.last_modified_by,
m1_0.last_modified_date,
m1_0.team_id,
m1_0.username
from
member m1_0
Hibernate:
select
t1_0.team_id,
t1_0.created_by,
t1_0.created_date,
t1_0.last_modified_by,
t1_0.last_modified_date,
t1_0.name
from
team t1_0
where
t1_0.team_id=?
Team과 Member를 하나씩 더 추가해보자
Team teamA = new Team();
teamA.setName("teamA");
em.persist(teamA);
Team teamB = new Team();
teamB.setName("teamB");
em.persist(teamB);
Member member1 = new Member();
member1.setUsername("member1");
member1.setTeam(teamA);
em.persist(member1);
Member member2 = new Member();
member2.setUsername("member2");
member2.setTeam(teamB);
em.persist(member2);
em.flush();
em.clear();
List<Member> members = em.createQuery("select m from Member m", Member.class).getResultList();
쿼리를 보면 엔티티에 대한 쿼리 1개와 참조 엔티티에 대한 2개의 쿼리가 나가는것을 볼 수 있다.
Hibernate:
/* select
m
from
Member m */ select
m1_0.member_id,
m1_0.created_by,
m1_0.created_date,
m1_0.last_modified_by,
m1_0.last_modified_date,
m1_0.team_id,
m1_0.username
from
member m1_0
Hibernate:
select
t1_0.team_id,
t1_0.created_by,
t1_0.created_date,
t1_0.last_modified_by,
t1_0.last_modified_date,
t1_0.name
from
team t1_0
where
t1_0.team_id=?
Hibernate:
select
t1_0.team_id,
t1_0.created_by,
t1_0.created_date,
t1_0.last_modified_by,
t1_0.last_modified_date,
t1_0.name
from
team t1_0
where
t1_0.team_id=?
하지만 지연로딩으로 설정한다면 아래와 같이 하나의 쿼리로 끝이 난다.
/* select
m
from
Member m */ select
m1_0.member_id,
m1_0.created_by,
m1_0.created_date,
m1_0.last_modified_by,
m1_0.last_modified_date,
m1_0.team_id,
m1_0.username
from
member m1_0
정리
가급적 지연 로딩만 사용(실무에서)
즉시 로딩을 적용하면 예상치 못한 SQL이 발생
즉시 로딩은 JPQL에서 N+1 문제를 일으킨다.
@ManyToOne, @OneToOne은 기본이 즉시 로딩 -> LAZY로 설정
@OneToMany, @ManyToMany 는 기본이 지연로딩
3. CASCADE(영속성 전이)
CASCADE란 특정 엔티티를 영속 상태로 만들 때 연관된 엔티티도 함께 영속 상태로 만드는 기능이다.
Parent 와 Child라는 엔티티가 있을 때 연관관계에 cascade 속성을 추가한다.
Child child1 = new Child();
child1.setName("child1");
Child child2 = new Child();
child2.setName("child2");
Parent parent = new Parent();
parent.addChild(child1);
parent.addChild(child2);
em.persist(parent);
em.flush();
em.clear();
Parent findparent = em.find(Parent.class, parent.getId());
findparent.getChildList().remove(0);
쿼리를 확인해보면 delete 쿼리가 나가고 있다.
Hibernate:
select
p1_0.member_id,
p1_0.name
from
parent p1_0
where
p1_0.member_id=?
Hibernate:
select
c1_0.parent_id,
c1_0.member_id,
c1_0.name
from
child c1_0
where
c1_0.parent_id=?
Hibernate:
/* delete for com.example.jpa.domain.Child */delete
from
child
where
member_id=?
실제 DB
parent
child
id가 1번인 데이터가 삭제된것을 볼 수 있다.
주의
참조가 제거된 엔티티는 다른 곳에서 참조하지 않는 고아 객체로 보고 삭제하는 기능
참조하는 곳이 하나일 때사용해야함!
특정 엔티티를 개별 소유할 때 사용
영속성 전이 + 고아 객체
CascadeType.ALL + orphanRemovel=true
스스로 생명주기를 관리하는 엔티티는 em.persist()로 영속화, em.remove()로 제거
두 옵션을 모두 활성화 하면 부모 엔티티를 통해서 자식의 생명 주기를 관리할 수 있음
도메인 주도 설계(DDD)의 AggreGrate Root 개념을 구현할 때 유용하다고 한다.
CascadeType.ALL 혹은 REMOVE와 orphanRemovel이 기능적으로 비슷해보이지만
orphanRemoval은 연관관계가 끊어진 엔티티를 삭제하는 반면, CascadeType.REMOVE는 부모 엔티티가 삭제될 때 연관된 자식 엔티티도 함께 삭제한다.
findMember = class com.example.jpa.domain.Member$HibernateProxy$gPJPsc5E
이 프록시 객체의 내부에는 target이라는 것이 있는데, 이것이 진짜 엔티티를 가르킨다.
초기에는 껍데기만 있고, ID값만 들고있는 가짜가 반환된다.
2. 프록시 특징
엔티티의 프록시 객체는 어떻게 생겼냐 하면, 프록시 객체는 실제 객체의 taget이라는 참조를 보관한다.
예를들어, Member엔티티 프록시 객체에서 getName을 호출하면,
프록시 객체는 실제 target에 있는 엔티티의 getName을 대신 호출한다.
그런데 처음에는 타겟이 없다. 왜냐하면 이걸 실제 DB에서 조회한 적이 없기 때문이다.
프록시의 특징은 실제 객체 엔티티를 상속받아서 만들어진다. 그래서 실제 클래스와 겉모양이 같다. 이는 하이버네이트가 내부적으로 여러 프록시 라이브러리를 이용해 만든다.
정리
실제 클래스를 상속 받아서 만들어짐
실제 클래스와 겉 모양이 같다.
사용하는 입장에서는 진짜 객체인지 프록시 객체인지 구분하지 않고 사용하면 됨(이론상)
프록시 객체는 실제 객체의 참조(target)을 보관
프록시 객체를 호출하면 객체는 실제 객체의 메소드 호출
3. 프록시 객체의 초기화
1) 프록시 객체가 초기화되는 과정
프록시 객체를 getReference로 가져왔을 때, member.GetName을 호출하면, target에는 Member의 값이 처음에는 없었다가, JPA가 영속성 컨텍스트에 Member 값을 요청한다.
그러면 영속성 컨텍스트가 DB를 조회해서 실제 엔티티 객체를 생성한다. 그리고 프록시 객체의 target에 연결을 시켜준다. 즉, 프록시 내부에는 Member target 이라는 진짜 객체 변수가 있다고 보면 된다.
그래서 프록시 객체에서 getName을 했을 때, target의 getName을 통해 실제 객체에 있는 getName이 반환된다.
2) 한번 초기화된 프록시는 다시 DB를 조회할 필요가 없다.
영속성 컨텍스트에서 초기화를 요청하는 부분이 중요하다. 프록시에 값이 없을 때 진짜 값을 달라고 요청하는 것이다. DB를 통해서 진짜 값을 가지고 와서 진짜 엔티티를 만드는 과정을 의미한다. 그리고 이것이 초기화를 의미한다.
그리고 한번 초기화 되면 target에 객체 값이 걸리기 때문에 다시 DB를 조회할 일은 없다. 그래서 getName을 2번 요청하더라도 쿼리는 한번만 나간다.
em.getReference()로 userName 조회 시 쿼리
Hibernate:
select
m1_0.member_id,
m1_0.created_by,
m1_0.created_date,
m1_0.last_modified_by,
m1_0.last_modified_date,
t1_0.team_id,
t1_0.created_by,
t1_0.created_date,
t1_0.last_modified_by,
t1_0.last_modified_date,
t1_0.name,
m1_0.username
from
member m1_0
left join
team t1_0
on t1_0.team_id=m1_0.team_id
where
m1_0.member_id=?
findMember.getUsername() = hello
findMember.getUsername() = hello
3) 실제 객체와 프록시 객체의 타입 비교
또한 타입비교를 할 때 == 비교를 사용하지 말고 instance of를 사용해야한다.
왜냐하면 같은 객체끼리의 비교는 괜찮지만, em.find()와, em.getReference()를 == 비교한다면 false가 나올 수 있기 때문이다.
Member member1 = new Member();
member1.setUsername("hello1");
em.persist(member1);
Member member2 = new Member();
member2.setUsername("hello2");
em.persist(member2);
em.flush();
em.clear();
Member findMember1 = em.find(Member.class, member1.getId());
Member findMember2 = em.getReference(Member.class, member2.getId());
System.out.println("findMember1.getClass() = " + findMember1.getClass());
System.out.println("findMember2.getClass() = " + findMember2.getClass());
System.out.println("findMember1 == findMember2 : " + (findMember1.getClass() == findMember2.getClass()));
이 경우엔 실제 객체와 프록시 객체가 비교되므로 false가 나온다.
== 연산자는 객체의 참조를 비교한다. 즉, 두 객체가 메모리 상에서 동일한 위치에 있는지를 확인하는 것이다.
그렇기 때문에, 실제 엔티티 객체와 그 엔티티의 프록시 객체가 서로 다른 메모리 위치에 있다면
== 연산자로 비교했을 때 결과는 false가 된다.
findMember1.getClass() = class com.example.jpa.domain.Member
findMember2.getClass() = class com.example.jpa.domain.Member$HibernateProxy$pNqeG26x
findMember1 == findMember2 : false
4) 영속성 컨텍스트에 엔티티가 이미 있을 때 em.getReference()
같은 id를 참조하는 경우, 이미 find() 하여 1차 캐시에 엔티티가 저장되어있는 상태라면, getReference() 하더라도 프록시가 아닌, 실제 객체를 반환한다.
Member member1 = new Member();
member1.setUsername("hello1");
em.persist(member1);
em.flush();
em.clear();
Member findMember1 = em.find(Member.class, member1.getId());
System.out.println("findMember1.getClass() = " + findMember1.getClass());
Member findMember1Refer = em.getReference(Member.class, member1.getId());
System.out.println("findMember1Refer.getClass() = " + findMember1Refer.getClass());
첫번째 이유는 1차캐시에 이미 실제 엔티티가 존재하기 때문이고, 두번째 이유는 JPA는 같은 엔티티의 같은 id라면 라면 항상 == 비교를 true를 보장하기 때문이다.
findMember1.getClass() = class com.example.jpa.domain.Member
findMember1Refer.getClass() = class com.example.jpa.domain.Member
JPA는 같은 엔티티와 id라면 항상 == 비교가 참이 되도록 보장해주기 때문에, getReference()후 find()를 하게 되면
둘 다 프록시 객체로 조회된다.
Member member1 = new Member();
member1.setUsername("hello1");
em.persist(member1);
em.flush();
em.clear();
Member refMember = em.getReference(Member.class, member1.getId());
System.out.println("refMember.getClass() = " + refMember.getClass());
Member findMember = em.find(Member.class, member1.getId());
System.out.println("findMember.getClass() = " + findMember.getClass());
System.out.println("refMember == findMember : " + (refMember == findMember));
그렇기에 재미있게도 refMember.getClass()가 호출되기 직전에 조회쿼리를 호출하지만, 프록시 객체로 조회되는것을 볼 수 있다.
refMember.getClass() = class com.example.jpa.domain.Member$HibernateProxy$a1lJoMHB
Hibernate:
select
m1_0.member_id,
m1_0.created_by,
m1_0.created_date,
m1_0.last_modified_by,
m1_0.last_modified_date,
t1_0.team_id,
t1_0.created_by,
t1_0.created_date,
t1_0.last_modified_by,
t1_0.last_modified_date,
t1_0.name,
m1_0.username
from
member m1_0
left join
team t1_0
on t1_0.team_id=m1_0.team_id
where
m1_0.member_id=?
findMember.getClass() = class com.example.jpa.domain.Member$HibernateProxy$a1lJoMHB
refMember == findMember : true
5) hibernate.LazyInitializationException - 영속성 컨텍스트에 값이 없거나 컨텍스트 자체가 닫힌 경우
Hibernate:
/* insert for
com.example.jpa.domain.Member */insert
into
member (created_by,created_date,last_modified_by,last_modified_date,username,member_id)
values
(?,?,?,?,?,?)
refMember.getClass() = class com.example.jpa.domain.Member$HibernateProxy$PJu5GIAI
could not initialize proxy [com.example.jpa.domain.Member#1] - no Session
org.hibernate.LazyInitializationException: could not initialize proxy [com.example.jpa.domain.Member#1] - no Session
정리
프록시 객체는 처음 사용할 때 한 번만 초기화
프록시 객체를 초기화 할 때, 프록시 객체가 실제 엔티티로 바뀌는 것은 아님. 초기화되면 프록시 객체를 통해서 실제 엔티티에 접근 가능
프록시 객체는 원본 엔티티를 상속받음. 따라서 타입 체크 시 주의 필요 (== 비교 대신, instance of 사용)
영속성 컨텍스트에 찾는 엔티티가 이미 있으면 em.getReference() 를 호출해도 실제 엔티티를 반환
영속성 컨텍스트의 도움을 받을 수 없는 준영속 상태일 때, 프록시 초기화하면 문제 발생(하이버네이트는 org.hibernate.LazyInitializationException 예외를 터트림)
하지만 DB에는 슈퍼- 서브타입 이라는 모델링 기법이 존재하는데, 이것이 객체의 상속관계와 유사하다.
상속관계 매핑이란, 객체의 상속, 구조와 DB의 슈퍼타입, 서브타입을 매핑하는것이다.
슈퍼-서브타입 모델링으로 공통된 속성들을 하나로 묶거나, 하나로 합칠 수 있다.
이렇게 슈퍼타입, 서브타입 논리 모델을 실제 물리 모델로 구현하는 방법들이 JPA에서 세 가지가 존재한다.
1. 데이터를 정규화시켜서 각각의 테이블로 변환하는 조인 전략
비즈니스적으로 중요하고 복잡할 때 쓴다.
기본적으로 세 전략 중 이 전략을 많이 사용한다.
슈퍼타입으로 사용할 상위 엔티티 생성 후 @Inheritance(strategy = InheritanceType.JOINED) 를 클레스에 추가한다.
또한, @DiscriminatorColumn 라는 어노테이션을 추가하여 테이블상에 DTYPE 이라는것을 추가하는데,
조인된 서브타입 테이블의 이름을 저장해 데이터를 구분하는데 도움을 준다.
(name속성을 변경하여 컬럼명을 DTYPE 외에도 다양하게 사용할 수 있다. )
상속받은 엔티티 클레스에 @DiscriminatorValue(value = "M") 를 추가해주면,(@DiscriminatorValue("M") 도 가능)
엔티티 명 대신 설정한 값인 M이 들어간다.
이후 아래처럼 하위 엔티티에서 상위 엔티티를 상속받으면 된다.
결론적으로 아래 코드에서 변경점 하나 없이 @ Inheritance의 stategy 속성 변경만으로 테이블 구조가 달라진다.
package com.example.jpa.domain;
import jakarta.persistence.*;
import lombok.Getter;
import lombok.Setter;
import java.util.ArrayList;
import java.util.List;
@Entity
@Getter
@Setter
@Inheritance(strategy = InheritanceType.JOINED)
@DiscriminatorColumn
public class Item {
@Id @GeneratedValue
@Column(name = "item_id")
private Long id;
private String name;
private int price;
private int stockQuantity;
@ManyToMany(mappedBy = "items")
private List<Category> categories = new ArrayList<>();
}
package com.example.jpa.domain;
import jakarta.persistence.Entity;
@Entity
public class Book extends Item{
private String author;
private String isbn;
}
package com.example.jpa.domain;
import jakarta.persistence.Entity;
@Entity
public class Album extends Item{
private String artist;
}
package com.example.jpa.domain;
import jakarta.persistence.Entity;
@Entity
public class Movie extends Item{
private String director;
private String actor;
}
상위 테이블과 하위 테이블 모두를 접근해야하므로 쿼리가 2번 나간다는 특징이 있다.
장점
테이블 정규화
외래 키 참조 무결성 제약조건 활용 가능
저장공간 효율화
단점
조회 시 조인을 많이 사용, 성능 저하
조회 쿼리가 복잡함
데이터 저장 시 INSERT SQL 2번 호출
가장 정석적인 전략이다.
2. 여러 테이블을 하나라 통합하는 단일 테이블 전략
논리 모델을 한 테이블로 구성하는 전략이다.
데이터도 얼마 안되고 너무 단순하고 확장할 일도 없을때 쓰면 좋다고 한다.
위에 상술한 @Inheritance 속성을 InheritanceType.SINGLE_TYPE으로 변경하면 된다.
Hibernate:
create table item (
price integer not null,
stock_quantity integer not null,
item_id bigint not null,
dtype varchar(31) not null,
actor varchar(255),
artist varchar(255),
author varchar(255),
director varchar(255),
isbn varchar(255),
name varchar(255),
primary key (item_id)
) engine=InnoDB
위 코드들을 보면, 각자의 세부 엔티티들은 상위 엔티티인 item을 확장했고,
그 item 테이블 쿼리를 보면 테이블에 세부 엔티티가 전부 들어간것을 볼수 있다.
장점
조인이 필요없으므로 일반적인 조회 성능이 빠름
조회 쿼리가 단순함
단점
자식 엔티티가 매핑한 컬럼은 모두 null 허용
단일 테이블에 모든 것을 저장하므로 테이블이 커질 수 있는 상황에 따라서 조회 성능이 느려질 수 있다.
3. 슈퍼타입으로 모으지 않고 서브타입에 각각 속성들을 포함시키는 구현 클래스마다 전략
@Inheritance 속성을 InheritanceType.TABLE_PER_CLASS 로 변경하면 된다.
상위 테이블을 없애고 각각의 하부 테이블에 상위테이블 값들을 넣는 방식이다.
참고로, 이 전략에서는 @DiscriminatorColumn 이 적용되지 않는다.
상위 테이블인 ITEM이 사라졌기 때문에, 구분할 필요가 없기 때문이다.
이 전략은 단순하게 값을 넣고 뺄 때는 딱 좋은데, 상위타입으로 엔티티를 find하게되면 문제가 생긴다.
Hibernate:
select
i1_0.id,
i1_0.clazz_,
i1_0.name,
i1_0.price,
i1_0.stock_quantity,
i1_0.artist,
i1_0.author,
i1_0.isbn,
i1_0.actor,
i1_0.director
from
(select
price,
stock_quantity,
id,
artist,
name,
null as author,
null as isbn,
null as actor,
null as director,
1 as clazz_
from
album
union
all select
price,
stock_quantity,
id,
null as artist,
name,
author,
isbn,
null as actor,
null as director,
2 as clazz_
from
book
union
all select
price,
stock_quantity,
id,
null as artist,
name,
null as author,
null as isbn,
actor,
director,
3 as clazz_
from
movie
) i1_0
where
i1_0.id=?
장점
서브 타입을 명확하게 구분해서 처리할 때 효과적
not null 제약조건 사용 가능
단점
여러 자식 테이블을 함께 조회 할 때 성능이 느림(UNION SQL)
자식 테이블을 통합해서 쿼리하기 어려움
@MappedSuperclass
테이블과는 관계 없고, 단순히 엔티티가 공통으로 사용하는 매핑 정보를 모으는 역할을 한다.
주로 등록일, 수정일, 등록자, 수정자 같이 전체 엔티티에서 공통적으로 사용하는 정보를 모을 때 사용한다.
package com.example.jpa.domain;
import jakarta.persistence.MappedSuperclass;
import lombok.Getter;
import lombok.Setter;
import java.time.LocalDateTime;
@Getter
@Setter
@MappedSuperclass
public abstract class BaseEntity {
private String createdBy;
private LocalDateTime createdDate;
private String lastModifiedBy;
private LocalDateTime lastModifiedDate;
}
------------------------------------
public class Team extends BaseEntity {...}
참고 : @Entity 클래스는 엔티티나 @MappedSuperClass로 지정한 클래스만 상속가능하다.