자바의 hashMap은 내부 배열의 길이가 64, 한 버킷의 요소 수가 8 이상이 되면 해당 배열의 요소들은 연결리스트가 아닌 레드-블랙 트리 기반의 트리노드로 구현된다.
putVal의 로직 중 다음 로직을 보면 binCount를 반복하면서 TREEIFY_THRESHOLD-1 값에 다다를 때 treeifyBin을 호출한다.
...
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
...
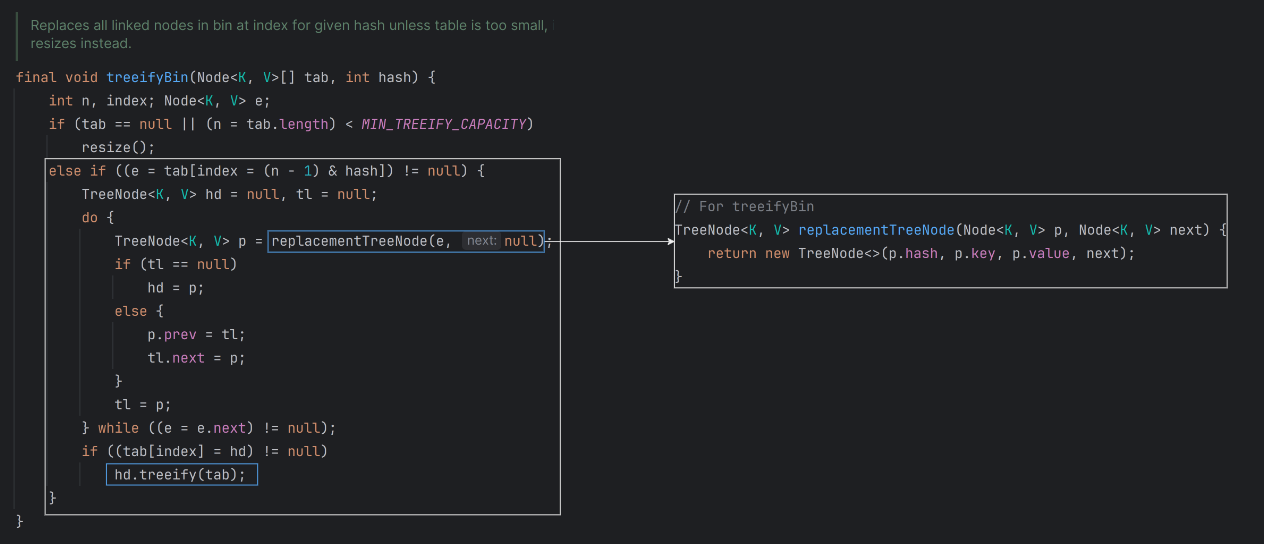
1. treeifyBin
첫번째 조건으로 배열의 길이를 측정하고 64 미만이라면 treeify하지 않고 resize()를 호출한다.
그 외 조건에서는 replacementTreeNode를 이용해 TreeNode를 생성하고 해당 버킷에 대한 treeify를 수행한다.
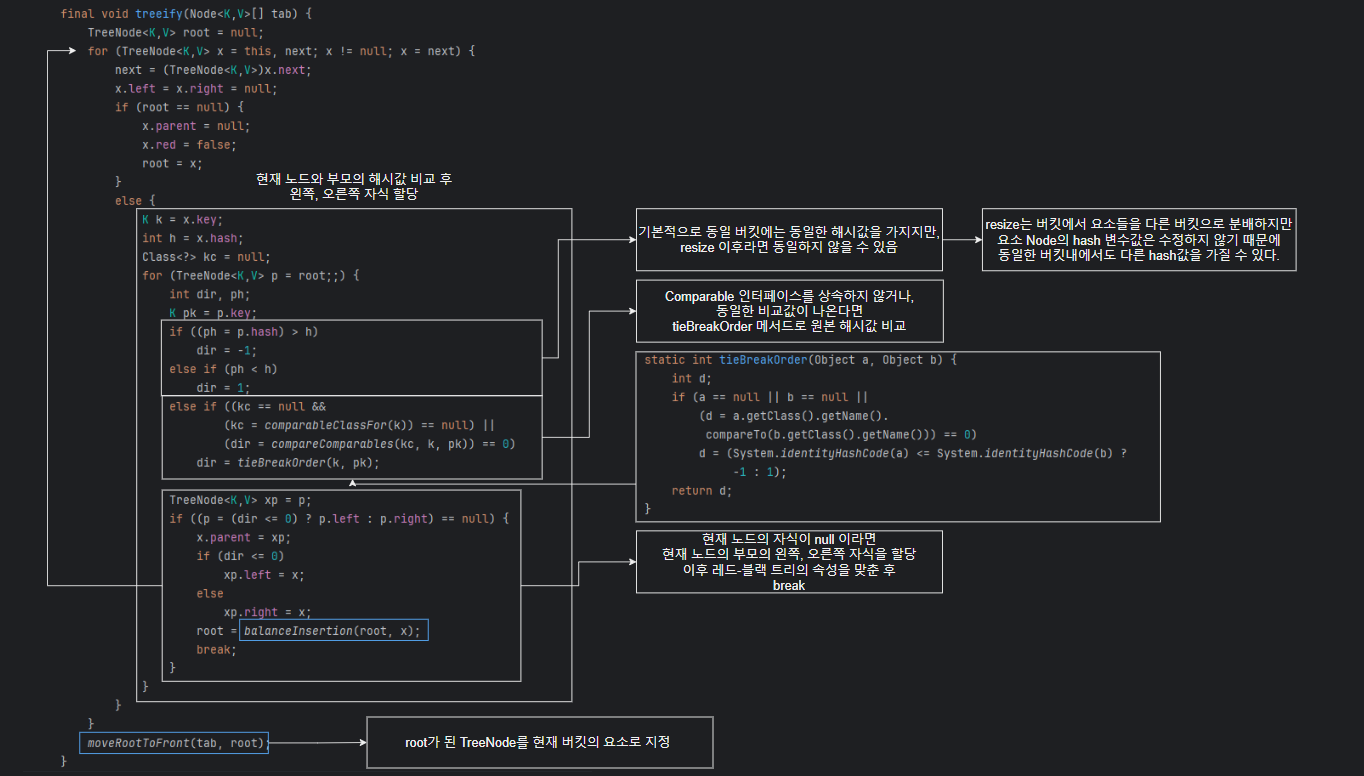
2. treeify
treeify는 해시맵의 내부배열 요소를 Node(연결리스트) 에서 TreeNode(레드-블랙 트리, 연결리스트 통합) 으로 변경하는 작업을 수행한다.
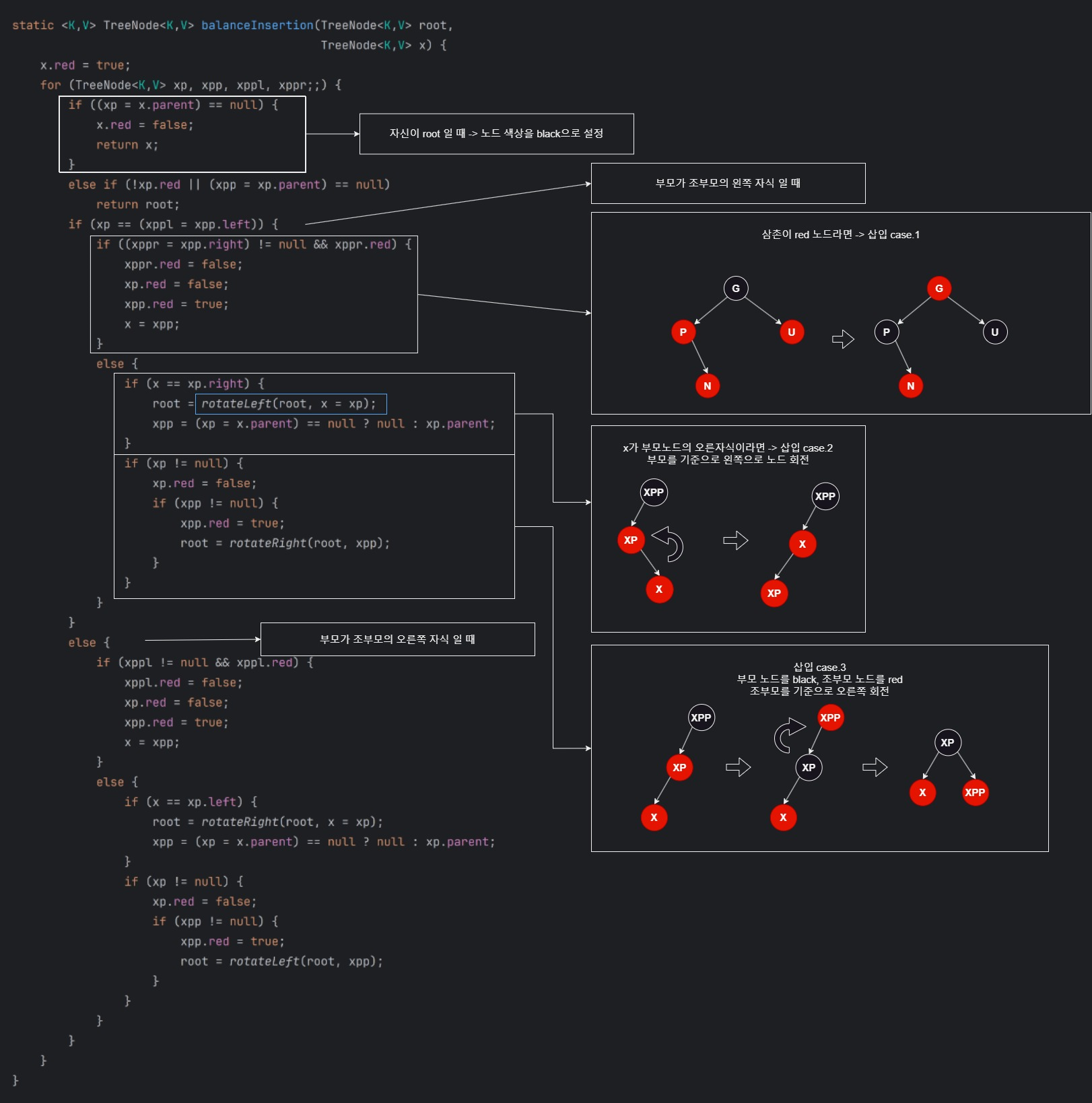
3.balanceInsertion
레드-블랙 트리의 속성에 맞게 노드 구조를 재조정한다.
4.moveRootToFront
메서드 이름만 보면 단순히 root를 해당 버킷의 요소로 할당만 하는것 같지만
추가적으로 root.next에 기존의 연결리스트를 참조한다.
여기서 중요한 점은 hashMap의 TreeNode는 레드-블랙 트리의 특성과 LinkedList의 특성을 동시에 가지며, 이 메서드에서는 treeify를 호출한 버킷의 요소를 기존의 Node(LinkedList) 형식에서 TreeNode(red-black tree)로 변환하고
root(TreeNode).next에 기존의 Node를 연결하여 순서를 계속 기억하고 있다는 점이다. 이 연결 순서를 기억하기 위해 putTreeVal 같은 연산을 시행할 때, 해당 메서드 내부에서는
TreeNode의 값만을 연산하는것이 아니라, Node의 순서또한 업데이트한다.
이는 효율성의 문제로 LinkedList형식으로 돌아갈 때 사용하는 untreeify를 위해서이다.
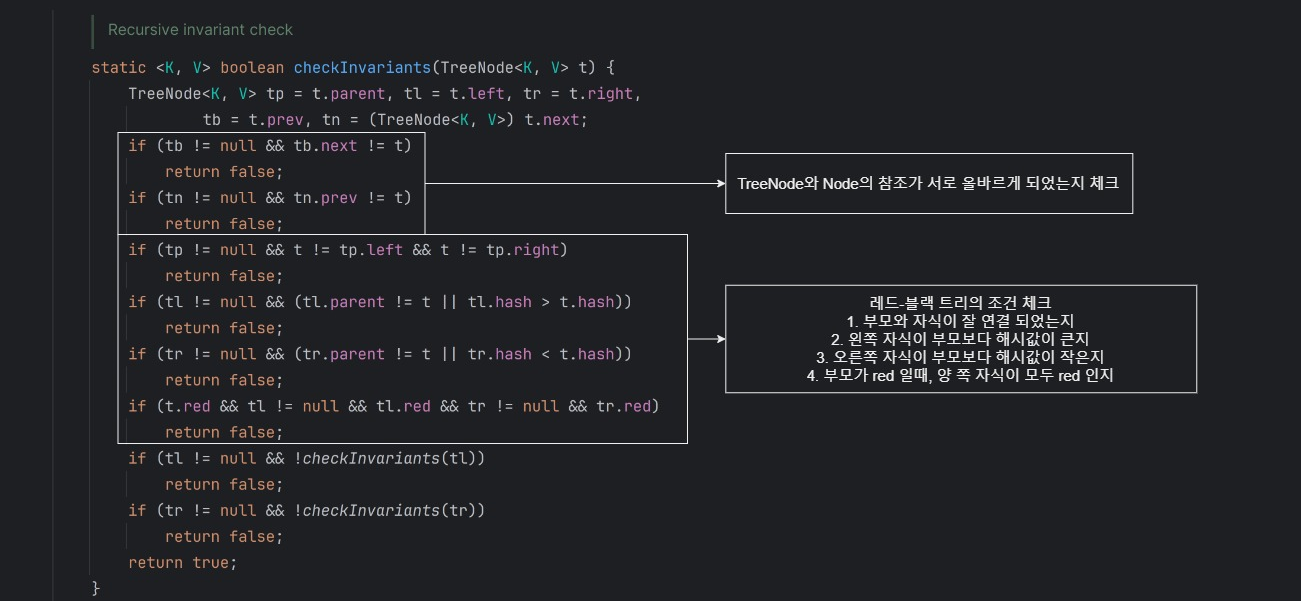
5. checkInvariants
Node -> TreeNode 형식으로 변환되면서 참조, 속성에 대해서 위반사항이 없는지 확인한다.
treeify를 정리하면서 해시맵이 단순히 연결리스트 -> 레드-블랙 트리 구조로 변경되는것이
아니라 레드-블랙 트리 + 연결리스트 구조를 합친 TreeNode로 변경되는것이 놀라웠다.
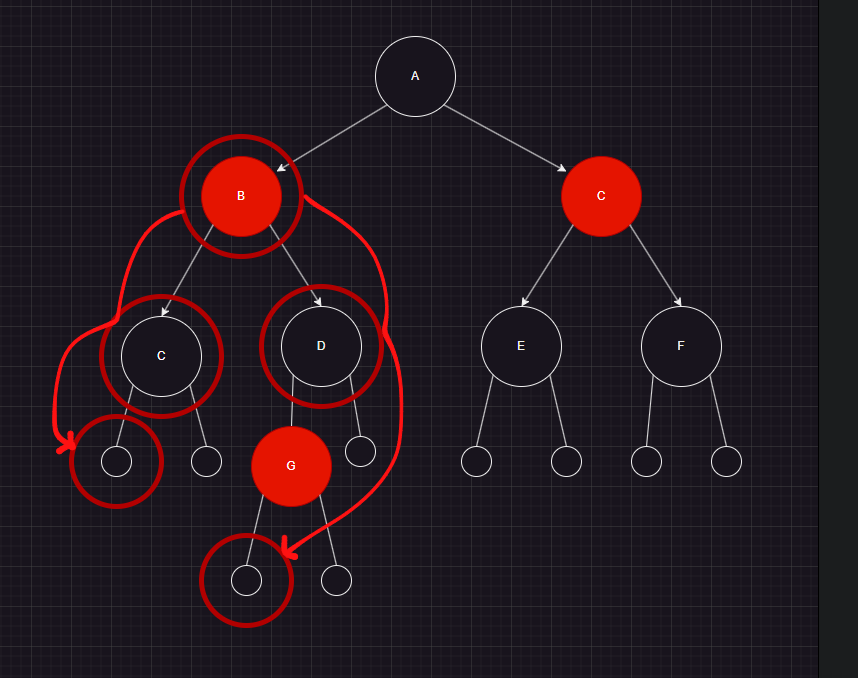
레드-블랙 트리의 각 노드들은 red 혹은 black 노드로 구성되어있고, 각 리프에는 nil이라는 임시 노드들이 존재하며, 일반 노드와 동급 취급한다.
nil 노드는 다음과 같은 특징을 지닌다. - 존재하지 않음을 의미하는 노드 - 자녀가 없을 때 자녀를 nil 노드로 표기 - 값이 있는 노드와 동등하게 취급 - RBT에서 leaf 노드는 nil 노드 - 모든 nil(leaf) 노드는 black
1. 속성
레드-블랙 트리는 다음과 같은 속성이 존재한다.
#1 : 모든 노드는 red 혹은 black 이다 #2 : 루트 노드는 black 이다 #3 : 모든 nill 노드는 black 노드이다 #4 : 노드가 red라면 자녀들을 black 이다 #5 : 임의의 노드에서 그 노드의 자손 nil 노드들 까지 가는 경로들의 black 수는 같다.(자기 자신은 카운트에서 제외)
여기서 다른 속성들은 이해가 되는데, 5번은 무슨 의미인지 헷갈린다. 무슨 의미일까?
그림과 같이 B 노드에서 시작해 C의 nil 노드와, G의 nil 노드까지의 black 노드의 수는 모두 2이다.
그외에도 어디든 nil 노드까지의 black 노드의 수는 2로 모두 동일하다.
이렇게 어디서든 모든 nil 노드까지의 black 노드의 수는 동일해야 한다는 것이 #5 규칙이다.
black height
특정 노드에서 nil 노드까지의 내려가는 경로에서 black 노드의 수를 black height 라고 한다.
RB 트리는 어떻게 균형을 잡을까?
삽입/삭제 시 주로 #4, #5 사항을 위반하며 이들을 해결하려고 구조를 바꾸다 보면 자연스럽게 트리의 균형이 잡힌다.
#4 : 노드가 red라면 자녀들을 black 이다
#5 : 임의의 노드에서 그 노드의 자손 nil 노드들 까지 가는 경로들의 black 수는 같다
2. 삽입
overveiw
삽입 과정은 다음과 같은 순서로 진행된다.
0. 삽입 전 RBT 속성을 만족한 상태 1. 삽입 방식은 일반 적인 BST와 동일 2. 삽입 후 RBT 위반 여부 확인 3. RBT 속성을 위반했다면 재조정 4. RB 트리 속성을 다시 만족
삽입 노드의 색
삽입하는 노드의 색은 언제나 red이다.
삽입 예시
최초에 50 노드를 삽입 하면 다음과 같은 형태가 된다.
두 nil 노드의 색은 black으로 고정되며 자연스럽게 #3 속성을 만족하게 된다.
#3 : 모든 nill 노드는 black 노드이다
하지만 50은 root 노드이므로 #2 속성을 위반하게 된다. 이때는 루트 노드를 black으로 바꾸면 해결된다.
#2 : 루트 노드는 black 이다
이렇게 노드 삽입 후 #2 의 속성을 위반한다면 black으로 변경해주면 해결된다.
이후 20을 삽입하면 자연스럽게 RBT의 모든 속성을 만족한다.
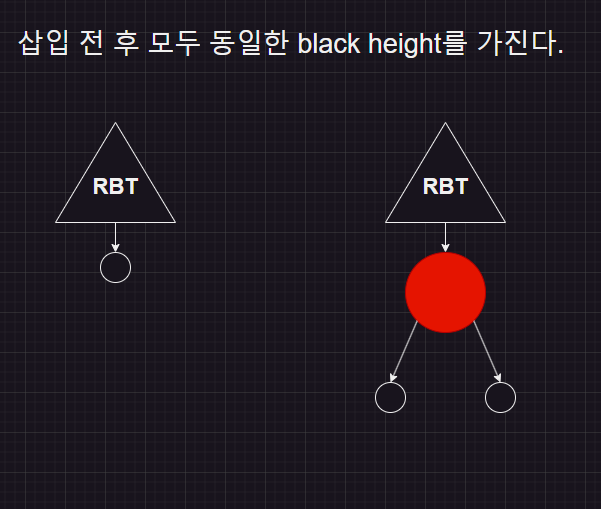
왜 새로 삽입하는 노드는 red인가?
red 노드로 삽입을 하면 black height의 변동이 없으므로 #5 속성을 만족하게 된다
#5 : 임의의 노드에서 그 노드의 자손 nil 노드들 까지 가는 경로들의 black 수는 같다
삽입 시 속성 해결
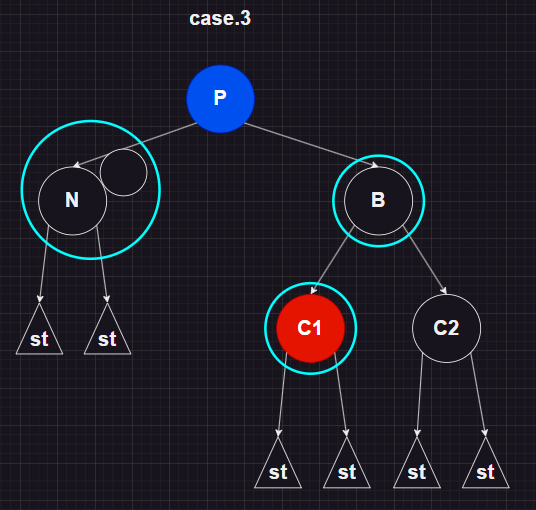
case3
삽입된 red 노드(N)가 부모(P)의 왼쪽 자식, 부모도 red 이고 할아버지(G)의 왼쪽 자식, 삼촌(U)은 black 이라면 부모와 할아버지의 색을 바꾼 후 할아버지 기준으로 오른쪽 회전
예시 상황
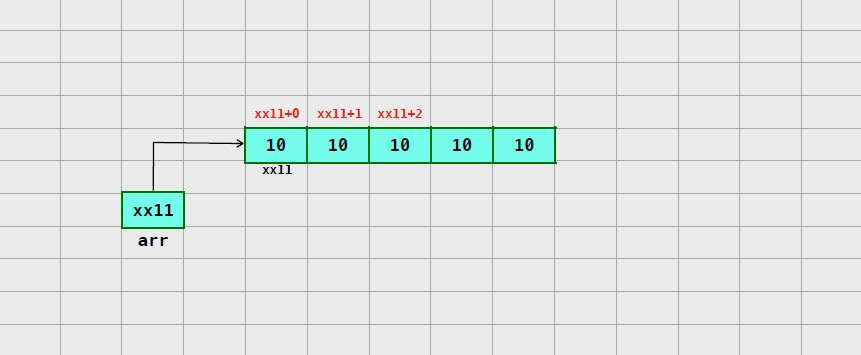
insert(10) 현재 상황에서는 레드 노드 자식이 레드 노드이므로, #4 속성을 위반한다.
#4 : 노드가 red라면 자녀들을 black 이다
BST 속성을 유지하며 #4 속성 위반을 해결하기 위해서는 회전이 필요하다 그러기 위해서 부모와 할아버지의 색을 교체한 후 할아버지 기준으로 오른쪽으로 회전시킨다.
case2
삽입된 red 노드(N)가 부모(P)의 오른쪽 자녀, 부모도 red고 할아버지(G)의 왼쪽 자녀, 삼촌(U)은 black 이라면 부모를 기준으로 왼쪽 으로 회전한 뒤 case3 방식으로 해결
예시 상황
insert(40)
20을 기준으로 왼쪽으로 회전하여 case.3과 동일하게 만들어준다. 이후 case.3의 방식으로 문제를 해결한다.
case1
삽입된 red 노드(N)의 부모(P)도 red, 삼촌(U)도 red 라면 부모와 삼촌을 black으로 바꾸고 할아버지(G)를 red로 바꾼 뒤 할아버지에서 다시 확인을 시작(루트인지 아닌지, 할아버지 부모도 red 노드인지)
예시 상황
아래 상황에서는 case.2 을 적용할 수 없다. 왜일까?
이 상황에서 case.2를 적용하면 다음처럼 20-10 관계에서 추가적인 문제가 생기기 때문이다. 그렇기에 삼촌이 red이면 case.1을 적용해야 한다.
case.1을 적용하여 부모와 삼촌은 black, 할아버지는 red로 변경한다. 이후 RBT의 5 속성에 위반하는지 확인한다.
3. 삭제
삭제 방식 overview
0. 삭제 전 RBT 속성을 만족한 상태 1. 삭제 방식은 일반적인 BST와 동일 2. 삭제 후 RBT 속성 위반 여부 확인 3. RBT 속성을 위반했다면 재조정 4. RBT 속성을 다시 만족
속성 위반 여부 확인 방법
RBT에서 노드를 삭제할 때 어떤 색이 삭제되는지가 속성 위반 여부를 확인할 때 매우 중요
삭제하려는 노드의 자녀가 없거나 하나라면 삭제되는 색 = 삭제되는 노드의 색
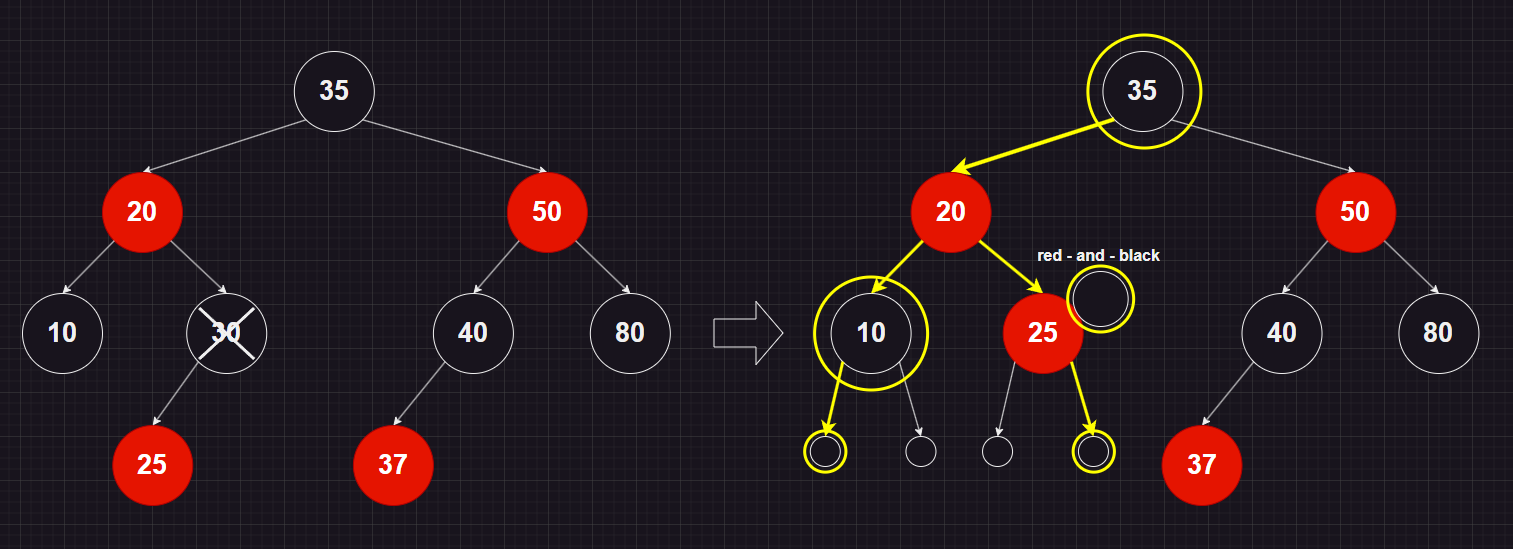
25 삭제 -> red 삭제 80 삭제 -> black 삭제 40 삭제 -> black 삭제
삭제하려는 노드의 자녀가 둘이라면 삭제되는 색 = 삭제되는 노드의 successor의 색 * successor : 해당 노드보다 큰 가장 작은 노드
20삭제 -> successor 25 -> red 삭제 35삭제 -> successor 37 -> red 삭제 50삭제 -> successor 80 -> black 삭제
삭제되는 색이 red라면 어떠한 속성도 위반하지 않는다.
#1 : 모든 노드는 red 혹은 black #2 : 루트 노드는 black #3 : 모든 nill 노드는 black #4 : 노드가 red라면 자녀들을 black #5 : 임의의 노드에서 그 노드의 자손 nil 노드들까지 가는 경로들의 black 수는 같다.
삭제되는 색이 black 이라면 #2, #4, #5 속성을 위반할 수 있다.
#2 : 루트 노드는 black #4 : 노드가 red라면 자녀들을 black #5 : 임의의 노드에서 그 노드의 자손 nil 노드들까지 가는 경로들의 black 수는 같다.
삭제되는 색이 black 일때
#2 위반 해결하기
루트 노드를 black으로 변환하면 된다
#5 위반 해결하기
extra black 부여
#5 속성을 다시 만족 시키기 위해 삭제된 색의 위치를 대체한 노드에 extra black을 부여한다.
extra black의 역할
경로에서 black 수를 카운트 할 때 extra black은 하나의 black으로 카운트 된다
예시 상황
delete(10) 10의 위치를 대체한 nil 노드에 extra black 부여 -> #5 속성 다시 만족
delete(30) 삭제된 색은 30의 black이었으므로 30의 위치를대체한 노드인 25에 extra black 부여 -> #5 속성 다시 만족
delete(50) 50을 제거하는경우 50은 자식이 둘다 존재하기 때문에 제거하게되면 50의 successor인 80과 값을 교체하고 black 노드를 제거하게 된다. black 노드를 제거하는 경우, 이를 대체하기 위한 extra black을 nil 노드에 부여한다.
정리
삭제되는 색이 black 이고 #5 위반일 때 extra black 부여 결과
extra black 을 부여받은 노드는 doubly black이 되거나 red-and-black이 된다
red - and - black 해결하기
red-and-black 을 black 으로 바꾸면 해결
doubly black 해결하기
doubly black을 제거하는 방법은 총 4가지 case로 분류됨
네가지 case로 분류할 때의 기준은 doubly black의 형제의 색과 그 형제의 자녀들의 색
doubly black 제거 케이스
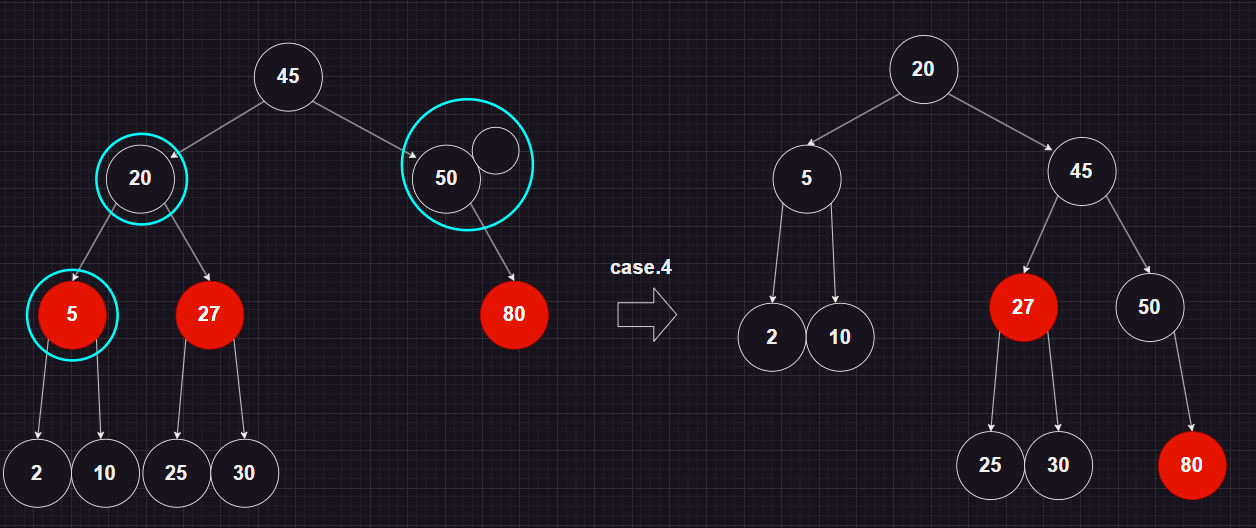
case.4
doubly black의 오른쪽 형제가 black 그 형제의 오른쪽 자녀가 red 일 때
오른쪽 형제는 부모의 색으로, 오른족 형제의 오른쪽 자녀는 black으로, 부모는 black으로 바꾼 후에 부모를 기준으로 왼쪽으로 회전하면 해결
예시 상황
delete(15)
case.3
doubly black의 오른쪽 형제가 black 그 형제의 왼쪽 자녀가 red 그 형제의 오른쪽 자녀는 black 일때
doubly black의 형제의 오른쪽 자녀를 red가 되게 만들어 이후엔 case4를 적용
예시 상황
delete(33)
case.2
doubly black의 형제가 black 그 형제의 두 자녀 모두 black 일때 doubly black과 그 형제의 black을 모아 부모에게 전달해 부모가 extra black을 해결하도록 위임한다
부모가 루트노드라면 black으로 바꿔서 해결 아니라면 case1,2,3,4 중에 하나로 해결
예시 상황
delete(40)
case.1
doubly black의 오른쪽 형제가 red 일 때 부모와 형제의 색을 바꾸고 부모를 기준으로 왼쪽으로 회전한 뒤 doubly black을 기준으로 case 2,3,4 중에 하나로 해결
그렇다면 equals는 왜 따라서 오버라이드 해야 하는 것일까? 해시코드만 동일하게 고정시키고, 저장, 조회한다면, equals는 왜 필요할까?
그것은 해시맵의 구조 자체가 한 인덱스에 하나의 데이터만 들어가는 구조가 아니기 때문이다. 즉, 해시 충돌이 발생한 인덱스의 경우, 정확히 어떤값을 찾아야할지 비교해야하므로, 우리는 equlas를 오버라이드하여, 해시맵이 보통 타입, 벨류들을 비교 후 동등한지 아닌지를 비교하여 반환하게 한다.
이것이 equals, hashCode 메서드가 해시관련 자료구조에서 오버라이딩해야하는 이유이다.
2. 멤버 인스턴스
다음은 멤버 인스턴스를 살펴보자.
2-1. 상수
DEFAULT_INITIAL_CAPACITY : 최초로 값을 넣을 때 생성되는 맵 내부 배열의 크기이다. 주석을 보면 2의 제곱만 가능하다고 되어있는데, 이것은 이후에 소개 할 resize 메서드와 관련이 있다.
MAXIMUM_CAPACITY : 해시맵 으로써 가질수 있는 길이의 최대 크기이다.
DEFAULT_LOAD_FACTOR : 배열의 크기를 늘리는 기준이다.
TREEIFY_THRESHOLD : 배열에서 한 버킷 안에 연결되어있는 노드가 연결될 수 있는 최대 수, 내부배열의 자료구조가 링크드리스트에서 트리맵으로 변경되는 기준1
UNTREEIFY_THRESHOLD : 트리노드에서 다시 배열로 전환되는 버킷 사이즈에 대한 값이다.
MIN_TREEIFY_CAPACITY : 배열의 길이를 의미하며, 내부배열의 자료구조가 링크드리스트에서 트리맵으로 변경되는 기준2
/**
* The default initial capacity - MUST be a power of two.
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
/**
* The maximum capacity, used if a higher value is implicitly specified
* by either of the constructors with arguments.
* MUST be a power of two <= 1<<30.
*/
static final int MAXIMUM_CAPACITY = 1 << 30;
/**
* The load factor used when none specified in constructor.
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
/**
* The bin count threshold for using a tree rather than list for a
* bin. Bins are converted to trees when adding an element to a
* bin with at least this many nodes. The value must be greater
* than 2 and should be at least 8 to mesh with assumptions in
* tree removal about conversion back to plain bins upon
* shrinkage.
*/
static final int TREEIFY_THRESHOLD = 8;
/**
* The bin count threshold for untreeifying a (split) bin during a
* resize operation. Should be less than TREEIFY_THRESHOLD, and at
* most 6 to mesh with shrinkage detection under removal.
*/
static final int UNTREEIFY_THRESHOLD = 6;
/**
* The smallest table capacity for which bins may be treeified.
* (Otherwise the table is resized if too many nodes in a bin.)
* Should be at least 4 * TREEIFY_THRESHOLD to avoid conflicts
* between resizing and treeification thresholds.
*/
static final int MIN_TREEIFY_CAPACITY = 64;
2-2 변수
/**
* The table, initialized on first use, and resized as * necessary. When allocated, length is always a power of two. * (We also tolerate length zero in some operations to allow * bootstrapping mechanics that are currently not needed.) */
transient Node<K,V>[] table;
/**
* Holds cached entrySet(). Note that AbstractMap fields are used
* for keySet() and values().
* */
transient Set<Map.Entry<K,V>> entrySet;
/**
* The number of key-value mappings contained in this map.
* */
transient int size;
/**
* The number of times this HashMap has been structurally modified
* Structural modifications are those that change the number of mappings in
* the HashMap or otherwise modify its internal structure (e.g.,
* rehash). This field is used to make iterators on Collection-views of
* the HashMap fail-fast. (See ConcurrentModificationException).
*/
transient int modCount;
/**
* The next size value at which to resize (capacity * load factor).
* * @serial
*/
// (The javadoc description is true upon serialization.
// Additionally, if the table array has not been allocated, this
// field holds the initial array capacity, or zero signifying
// DEFAULT_INITIAL_CAPACITY.)
int threshold;
/**
* The load factor for the hash table.
* * @serial
*/
final float loadFactor;
3. 기본 생성자
Stack, ArrayDeque와는 다르게, 초기화 할 때 내부 배열의 크기를 정하지 않는다.
/**
* Constructs an empty {@code HashMap} with the default initial capacity
* (16) and the default load factor (0.75). */public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
4. 삽입
해시맵에서는 객체의 해시값 외에 자체적인 내부 해시값을 객체에 부여하며, 해시충돌 수, 배열의 크기에 따라 연결리스트에서 트리노드로 변환되기도 하며, 반대의 경우도 있다. 이 글에서는 연결리스트 섹션을 중심으로 정리하고자 한다. 각각의 파라미터는 다음과 같다.
4-1. put
put 메서드에서는 hash라는 메서드를 통해 객체의 해시코드를 해시맵에 사용할수 있게 내부용 해시코드를 생성한다.
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
4-2. putVal
hash : 내부용 해시코드 key : 키 value : 값 onlyIfOnlyAbsent : 참이면, 동일한 키의 데이터가 이미 저장되어있을 때 값을 덮어 씌우지 않는다. evict : LinkedHashMap에서 사용되며, 해시맵 자체에서는 단독으로 사용되지 않는다.
/**
* Implements Map.put and related methods. * * @param hash hash for key
* @param key the key
* @param value the value to put
* @param onlyIfAbsent if true, don't change existing value
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//1
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//2
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
//3
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
//4
else {
for (int binCount = 0; ; ++binCount) {
//4-1
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
//4-2
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
//5
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);//미구현
return oldValue;
}
}
//6
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);//미구현
return null;
}
(1) 내부 배열이 생성되지 않은 경우에는 resize 메서드를 이용하여 내부 배열을 초기화한다.
//1
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
(1-1) 기존의 내부 배열이 MAXIMUM_CAPACITY 이상이면 저장가능한 데이터 수량(threshold)을 최대치로 변경하고 그대로 반환한다.
(1-2) 내부 배열을 2배로 늘린 값이 MAXIMUM_CAPACITY 보다 작고, 기존의 내부 배열이 DEFAULT_INITIAL_CAPACITY 이상이면 newThr(데이터 최대 저장 수) 또한 기존의 oldThr의 2배로 늘린다.
(2)
//2
//2-1
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
//2-2
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
(2-1) 주석에는 '최초 용량이 threshold에 할당되어 있다' 라고 적혀있다. 언뜻 조건을 보면 이상하게 느껴진다. (1)의 oldCap이 0 이하이고, oldThr 가 0보다 큰 경우는 뭘까?
//2-1
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
답은 생성자에 있었다. (1)을 보면, 최초 내부 용량을 tableSizeFor메서드를 이용해서 threshold로 전송하고있다. 내부 배열 크기를 결정하는 변수가 따로 존재하지 않아, threshold를 이용해 임시적으로 initialCapacity를 전송한 것으로 보인다.
/**
* Constructs an empty {@code HashMap} with the specified initial
* capacity and load factor. * * @apiNote
* To create a {@code HashMap} with an initial capacity that accommodates
* an expected number of mappings, use {@link #newHashMap(int) newHashMap}.
* * @param initialCapacity the initial capacity
* @param loadFactor the load factor
* @throws IllegalArgumentException if the initial capacity is negative
* or the load factor is nonpositive */public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
//1
this.threshold = tableSizeFor(initialCapacity);
}
(2-2) 기본 생성자로 해시맵을 생성 했을 때의 로직이다.
//2-2
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
(3) (2-1) 의 경우, oldThr로 newCap은 값이 할당되지만, newThr는 따로 값이 초기화되지 않으므로, newThr값을 연산하여 threshold에 대입한다.
//3
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
큐는 FIFO 자료구조이다. 처음 넣은 데이터가 처음 반환된다는 것인데, 실생활의 예를 들면, 식당에서 밥을 먹기 위해 줄을 서는것을 볼 수있다. 맨 앞에서면 맨 먼저 입장한다.
Deque는 'Double Ended Queue'의 줄임말로, 기존 Queue의 개념을 확장한 일반화된 형태다.
이 자료구조는 양쪽 끝에서 데이터의 삽입과 삭제가 가능하며, 그래서 Queue와 Stack의 기능을 모두 포함하고 있다.
이로 인해 Deque는 Queue나 Stack보다 더 유연하고 다용도로 사용될 수 있다.
이전에 Stack 자료구조에서 설명했듯이, 양 LIFO,FIFO 를 모두 구현하는 자료구조인데, 원래는 순수 FIFO의 기능을 하는 큐 구현체를 소개하려 했지만, 생각보다 순수하게 FIFO만을 구현하는 구현체가 많이 없고, 스레드 세이프한 자료구조들이 많아 소개하기 복잡할것같아, deque를 FIFO 자료구조 소개 수단으로 채택했고, 그 구현체 중 하나인 ArrayDeque로
중심으로 설명하고자 한다.
ArrayDeque
이 ArrayDeque에는 사실 스텍과 큐의 메서드 모두가 정의되어있다.
ArrayDeque 인터페이스인 Deque의 문서를 읽어보면, 이에 대해서 다음과 같이 보여준다.
Stack, Queue에서의 메서드와 Deque에서 동일한 기능을 하는 메서드를 소개한다.
Deque는 Stack, Queue의 메서드를 모두 사용할 수는 있지만, 코드를 뜯어보면 결국 구현로직은 아래처럼 Deque메서드를 사용하기 때문에, Deque의 메서드 중심으로 설명하고자 한다.
1. 생성자
일단 생성자부터 살펴보자
/**
* Constructs an empty array deque with an initial capacity * sufficient to hold 16 elements. */
public ArrayDeque() {
elements = new Object[16 + 1];
}
그런데 주석을 보니, 처음부터 의문이 생긴다. 주석에서는 16개의 요소를 가지고있다고 하는데 왜 실제 구현에서는 크기가 16+1 일까?
이는 순환큐(Circular Queue)와 관련이 있다. 그럼 순환 큐는 큐와 어떻게 다르냐? 큐는 우리가 알고있는 FIFO 자료구조 형식이고,
이런 Queue는 LinkedList, ArrayDeque같이 여러 방식으로 구현이 가능하다.
Queue, Stack, List와 같은 개념적인 자료구조들은 추상 데이터 타입(ADT)으로 분류하는데, ADT는 데이터와 그 데이터에 적용할 수 있는 연산들을 정의하지만, 구체적인 구현 방식은 정의하지 않는다.
순환 큐 는 큐라는 자료구조의 구체적인 구현 구조라고 보면 된다.
이 순환 큐는 배열 구조로 구현되는데, 이를 위해 ArrayDeque는 head, tail을 추가적으로 선언한다.
그럼 이제 우리는 순환 큐가 큐의 구현 방식 중 하나 이고, head, tail은 순환 큐를 위한 것을 알았다. 그럼, 순환큐는 왜 이 head, tail이 필요한가? 그리고 이 head, tail은 정확히 무엇을 의미하는가?
삽입과정을 통해 알아보자.
2. 삽입
public void addLast(E e) {
if (e == null)
throw new NullPointerException();
final Object[] es = elements;
es[tail] = e;
if (head == (tail = inc(tail, es.length)))
grow(1);
}
static final int inc(int i, int modulus) {
if (++i >= modulus) i = 0;
return i;
}
ArrayDeque를 처음 생성하고, 첫 값을 넣을 때를 예를 들어보자.
생성자를 보면 최초 생성시 배열의 총 길이는 17이므로 내부에는 17개의 배열을 생성하며,
실제로는 16개의 배열만 사용한다. 여기서 head,tail은 배열의 가장 앞의 요소 인덱스, 가장 마지막 요소 인덱스를 의미한다.
클레스에서 맴버변수는 자동으로 초기화되므로, head, tail = 0이 된다. 총 17개의 배열이 있으며, 마지막 따로 표시한 배열은 값을 저장하는데 사용하지 않고, 해당 인덱스가 끝에 도달했는지 여부를 비교할때 사용한다. (빈칸은 모두 null이다.)
그럼 es[0], 즉 첫번째 배열은 "a"가 된다.
이제 head == tail ,즉 배열이 가득 찼는지 판별한다. 동일하다면, 배열이 가득 찼다는 의미이므로, 배열 크기를 늘릴것이고, 아니라면 늘리지 않는다.
inc메서드는 tail 인덱스가 마지막 배열을 넘어서는지 확인하고,
아니라면 그대로 tail을 반환할것이고, 넘어간다면, tail을 0으로 변경한다.
현 상황에서는 1을 반환하므로 tail = 1이 되고, 배열이 가득차지 않았으므로, grow는 호출되지 않는다.
grow는 단순하게 이야기하면 배열을 늘려주는 메서드이다.
배열의 크기를 비교해서 작으면 2배 정도를 늘리고, 크다면 원본의 절반의 크기를 늘린다.
이후 늘어난 배열 크기만큼 요소들의 위치를 재정렬한다.
private void grow(int needed) {
// overflow-conscious code
final int oldCapacity = elements.length;
int newCapacity;
// Double capacity if small; else grow by 50%
int jump = (oldCapacity < 64) ? (oldCapacity + 2) : (oldCapacity >> 1);
if (jump < needed
|| (newCapacity = (oldCapacity + jump)) - MAX_ARRAY_SIZE > 0)
newCapacity = newCapacity(needed, jump);
final Object[] es = elements = Arrays.copyOf(elements, newCapacity);
// Exceptionally, here tail == head needs to be disambiguated
if (tail < head || (tail == head && es[head] != null)) {
// wrap around; slide first leg forward to end of array
int newSpace = newCapacity - oldCapacity;
System.arraycopy(es, head,
es, head + newSpace,
oldCapacity - head);
for (int i = head, to = (head += newSpace); i < to; i++)
es[i] = null;
}
}
grow메서드의 로직이 잘 이해가 안된다면 이런 Deque 내부 배열이 있다고 예를 들어보자
현재 상황은 ArrayDeque에 1,2,3을 전부 삽입한 경우이다.
여기서 addLast 메서드는 head, tail이 동일하므로 grow(1) 을 실행한다.
Object[] integer = {1,2,3};
배열의 크기가 3 이므로, newCapacity = 8 이 된다.
현재 head == tail && head != null 이므로, 재정렬을 시행한다.
제거되어야 할 배열을 정리한다. 동시에 head의 값도 맞게 할당한다.
3. 반환
public E removeFirst() {
E e = pollFirst();
if (e == null)
throw new NoSuchElementException();
return e;
}
public E pollFirst() {
final Object[] es;
final int h;
E e = elementAt(es = elements, h = head);
if (e != null) {
es[h] = null;
head = inc(h, es.length);
}
return e;
}
static final <E> E elementAt(Object[] es, int i) {
return (E) es[i];
}
반환은 배열 크기를 정하는 로직은 필요 없으므로 상대적으로 쉬운 구조이다.
해당 배열 요소를 가져오고, null 처리하며, head를 1 증가 시킨 후
배열 요소를 반환한다.
이러한 ArrayDeque는 싱글스레드에서 사용하도록 구현되었으므로 멀티스레드 환경에서는 사용을 주의해야한다.
시작하기에 앞서, 자바에서는 Stack보다는 이후에 나온 Deque 구현체의 사용을 권장한다.
Deque는 LIFO,FIFO를 모두 지원하는 자료구조이다.
1. 상속
이제 자바의 Stack을 뜯어보자. Stack은 Vector라는 구현체를 상속하고있다.
public class Stack<E> extends Vector<E> {}
Vector란 ArrayList와 유사하게 배열의 크기를 조절하는 자료구조로, ArrayList 이전에 구현된 자료구조이다.
이 둘은 기능적으로는 유사한점이 많지만, Vector는 다중 스레드에, ArrayList는 단일 스레드에 적합하다.
2. 삽입
먼저 삽입을 알아보자.
Stack
public E push(E item) {
addElement(item);
return item;
}
Vector
public synchronized void addElement(E obj) {
modCount++;
add(obj, elementData, elementCount);
}
private void add(E e, Object[] elementData, int s) {
if (s == elementData.length)
elementData = grow();
elementData[s] = e;
elementCount = s + 1;
}
Vector의 add 메서드를 살펴보는데 궁금한점이 생겼다.
우리는 보통 List같은 자료구조로 데이터를 저장할 때 제네릭 타입을 이용해서 한가지 타입으로만 저장한다.
여기서 제네릭이란, <> 를 의미하며, 컴파일 시 타입을 체크해준다.
아래 예제에서는 <Integer>가 제네릭이며, Integer를 제네릭타입으로 지정한것이다.
List<Integer> numbers = new ArrayList<>();
근데 Vector의 맴버인스턴스를 확인해보면 배열의 타입이 Object로 되어있다.
public class Vector<E>
extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
/**
* The array buffer into which the components of the vector are * stored. The capacity of the vector is the length of this array buffer, * and is at least large enough to contain all the vector's elements. * * <p>Any array elements following the last element in the Vector are null.
* * @serial
*/
@SuppressWarnings("serial") // Conditionally serializable
protected Object[] elementData;
/**
* The number of valid components in this {@code Vector} object.
* Components {@code elementData[0]} through
* {@code elementData[elementCount-1]} are the actual items.
* * @serial
*/
protected int elementCount;
/**
* The amount by which the capacity of the vector is automatically * incremented when its size becomes greater than its capacity. If * the capacity increment is less than or equal to zero, the capacity * of the vector is doubled each time it needs to grow. * * @serial
*/
protected int capacityIncrement;
...
즉, 제네릭으로 타입체크를 한 후 자료구조에 저장을 하면
타입이 제네릭 타입으로 저장되는게 아니라,
Object로 저장되는 것이다.
3. 반환
Stack
public synchronized E pop() {
E obj;
int len = size();
obj = peek();
removeElementAt(len - 1);
return obj;
}
public synchronized E peek() {
int len = size();
if (len == 0)
throw new EmptyStackException();
return elementAt(len - 1);
}
여기서 elementCount는 요소의 수량을 반환하는것 같고, elementAt은 해당 인덱스의 값을 반환하는것 같다.
removeElementAt은 지정한 요소를 제거하는것 같은데, 로직이 뭔가 많다.
여기서 j는 뭘 의미하고, System.arraycopy는 무엇일까?
Vector
public synchronized int size() {
return elementCount;
}
public synchronized void removeElementAt(int index) {
if (index >= elementCount) {
throw new ArrayIndexOutOfBoundsException(index + " >= " +
elementCount);
}
else if (index < 0) {
throw new ArrayIndexOutOfBoundsException(index);
}
int j = elementCount - index - 1;
if (j > 0) {
System.arraycopy(elementData, index + 1, elementData, index, j);
}
modCount++;
elementCount--;
elementData[elementCount] = null; /* to let gc do its work */
}
public synchronized E elementAt(int index) {
if (index >= elementCount) {
throw new ArrayIndexOutOfBoundsException(index + " >= " + elementCount);
}
return elementData(index);
}
j가 무엇인지 알려면, 일단 System.arraycopy가 어떤 역할을 하는지부터 알아야 한다.
이름을 보면 배열을 복사한다는것같은데, 파라미터는 또 왜이리 많은가?
코드를 뜯어보면 다음처럼 구성되어있다.
여기서 native 라는 선언은, 자바 코드가 아닌, c나 c++같은 로우레벨 언어로 구현된 메서드라는 의미이다.
public static native void arraycopy(Object src, int srcPos,
Object dest, int destPos,
int length);
Object src : 원본 배열 int srcPost : 복사를 시작할 첫번째 인덱스 Obejct dest : 목적 배열 destPos : 목적배열에서 복사한 값을 할당할 첫번재 인덱스 length : 복사할 배열 요소의 수
실제로 적용해보면 다음과 같다. 정말 단순히 배열값을 복사하는 메서드이다.
String[] src = {"a","b","c","d","e"};
String[] dest = new String[5];
System.arraycopy(src,2,dest,0,3);
for (String s : dest) {
System.out.print(s + " ");
}
---
c d e null null
이번엔 src와 dest에 모두에 src를 넣고 실행해보자. 1인덱스 요소부터 3개의 요소를 원본의 맨 처음 부분부터 할당한다.
String[] arr = {"a","b","c","d","e"};
System.arraycopy(arr,1,arr,0,3);
for (String s : arr) {
System.out.print(s + " ");
}
---
b c d d e
b c d d e 가 된 이유는 원본 배열에 붙여 넣었으므로,
원본배열 : [a,b,c,d,e] 복사 요소 : b,c,d 배열 할당 : [b,c,d,d,e]
순서로 할당되기 때문이다.
이번엔 하나의 값만을 제거한 후 배열을 앞으로 당기는 예를 보자.
String[] arr = {"a","b","c","d","e"};
System.arraycopy(arr,1,arr,0,4);
arr[arr.length-1] = null;
for (String s : arr) {
System.out.print(s + " ");
}
---
b c d e null
이제 다시 벡터의 removeElement 메서드를 보면 이해가 좀더 쉽다.
이제 우리는 j가 삭제한 요소 뒤에 존재하는 요소들의 수량이라는것을 알았고,
System.arraycopy는 지정한 배열 요소를 복사하는 기능이며
상황에 따라 같은 배열의 값을 제거하고, 앞으로 당기는 역할을 할 수 있다는것을 알았다.
전체적인 로직은 이렇다.
삭제하고자 하는 배열의 인덱스가 마지막이면 바로 마지막 인덱스를 null 처리한다. 그렇지 않다면, arraycopy를 이용해 값을 제거하고 마지막의 불필요한 배열을 null처리한다.
왜 JVM의 스택 영역은 LIFO인것일까?
왜 스택 영역은 LIFO인가?
그전에, LIFO,FIFO의 차이는 뭘까?
처음엔 단순히 LIFO,FIFO의 차이는 '첫번째들어간 데이터가 나오는 순서의 차이' 로만 이해했지만,
지금은 LIFO,FIFO의 차이는 '데이터의 실행 시점의 차이'에 있다고 생각한다.
LIFO는 마지막 데이터가 가장 마지막으로 조회되지만, 가장 먼저 실행된다. 하지만 FIFO는 첫번째 데이터가 가장 먼저 실행된다. 즉, 조회는 동일하지만, 실행 시점에 있어서 차이가 있다는 의미다.
스택 영역은 메모리 호출 순서를 관리하는 곳인데, 말 그대로 Stack, LIFO로 구현된다. 그럼 왜 스택영역은 FIFO로 구현되면 안될까?
답은 간단했다. FIFO는 첫번째 실행된 메서드가 가장먼저 연산되어야 한다. 하지만 재귀같은 내부에 다른 메서드가 포함되어있는 메서드의 경우에는 어떤가? 첫번째 메서드가 실행이 완료되기전에 내부 메서드의 연산이 종료되고, 이후에 그 연산값을 이용해 첫번째 메서드가 연산을 완료한다.
즉, FIFO로 메모리 호출이 구현된다면 첫번째 메서드가 실행되면서 두번째 메서드를 실행하고, 첫번째 메서드는 연산을 기다린다. 하지만, 두번째 메서드는 실행되지 않는다. 왜냐? 첫번째 메서드가 종료되지 않았으니까!
하지만 LIFO는 조금 다르다 첫번째 메서드가 실행되면, 내부에서는 또 메서드를 실행한다.
그리고 가장 마지막 메서드의 연산값, 즉 마지막 메서드가 종료되면, 그 이전 메서드가 실행되게 된다.
LinkedList는 Node라는 인스턴스변수를 가지는 자료구조이다. 쉽게 표현하자면 LinkedList는 기차 라는 전체적인 틀 이고, Node는 이 기차의 연결된 열차로 보면 이해하기가 쉽다. 즉, node는 서로 연결되어있는 노드의 위치와, 자신이 가지고 있어야 할 값만을 가지고 있다.
LinkedList의 인스턴스변수 는 대략적으로 이렇게 구성되어있다. 여기서 frist와 last는 말 그대로 노드의 처음과 마지막을 의미하는데, 이 first, last를 기준으로 노드들을 추가,제거,순회한다.
1. 구조
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
{
transient int size = 0;
/**
* Pointer to first node.
*/
transient Node<E> first;
/**
* Pointer to last node.
*/
transient Node<E> last;
LinkedList 내부에 구현되어있는 Node 구현은 다음과 같다.
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
이와같이 next와, prev가 존재하는 노드를 양방향리스트 라고 부른다.
2. add
우리가 처음 LinkedList를 생성하면 다음과 같은 상황이 연출된다. 객체는 초기화가 되므로 선언만 되었던 변수들이 각자 초기화가 되면서 0, null을 할당한다.
여기서 다음과 같이 값을 추가하면,
linkedList.add("firstValue");
다음과 같은 코드가 호출된다. linkLast 메서드를 5단계로 분류했다.
public boolean add(E e) {
linkLast(e);
return true;
}
void linkLast(E e) {
final Node<E> l = last; //1
final Node<E> newNode = new Node<>(l, e, null); //2
last = newNode; //3
if (l == null)
first = newNode;
else
l.next = newNode;
size++; //4
modCount++; //5
}
이 부분은 현재 last노드를 임시로 비교하고자 변수로 선언한다.
final Node<E> l = last; //1
그리고 다음과 같이 새 노드를 생성한다.
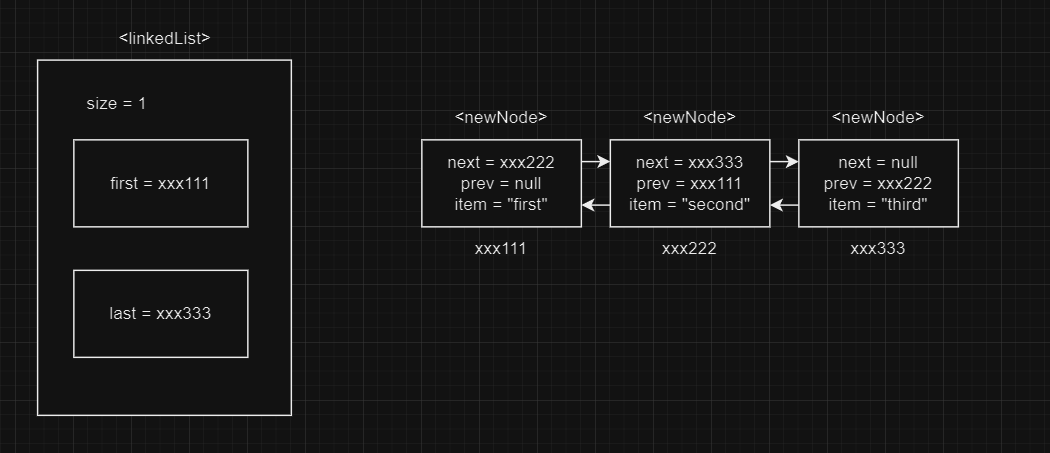
final Node<E> newNode = new Node<>(l, e, null); //2
시각적으로 표현하면 다음과 같다. 최초 삽입 시에는 last도 null이므로 결국 prev = null이 된다.
여기서는 linkdList의 last를 직접적으로 newNode로 지정한다. 만약 inkedList에 아무런 데이터도 없을 때에는 newNode를 최초,최후 노드로 지정한다. 그렇지 않다면, 기존에 데이터가 있던 상황이라면, l.next, 즉 마지막 노드의 다음 노드로 newNode를 지정한다.
last = newNode; //3
if (l == null)
first = newNode;
else
l.next = newNode;
단순하게 시각화 한다면 다음과 같다
최초 노드 삽입 시
기존 노드에 추가적으로 삽입 시(size=1)
이제 linkdList에 newNode가 추가되었으니, size를 증가시켜준다.
size++; //4
그런데 이상한점을 발견한다. 분명, modCount는 인스턴스 변수에 없었는데, 어디서 나타난걸까?
modCount++; //5
modCount는 AbstractList로 구현된 것이고, LinkedList는 이를 계승 했기 때문에 가능하다.
modCount는 수정된 횟수를 추적하는데 이것은 Iterator를 위해 사용된다. Iterator는 조회의 역할을 위해 사용하므로 순회 중 데이터 변경이 감지되면, 즉 modCount의 변경이 감지되면 예외를 발생 시켜서 데이터 무결성을 방지하는 역할이라고 이해하고 있다.
3. remove
이번에는 제거 로직을 알아보자.
LinkedList<String> linkedList = new LinkedList<>();
linkedList.add("first");
linkedList.add("second");
linkedList.add("third");
remove를 호출하면
linkedList.remove("firstValue");
LinkedList는 null도 데이터로 취급하기에 null인 경우와 아닌 경우를 나누어서 제거한다.
public boolean remove(Object o) {
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item; //1
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) { //2
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) { //3
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
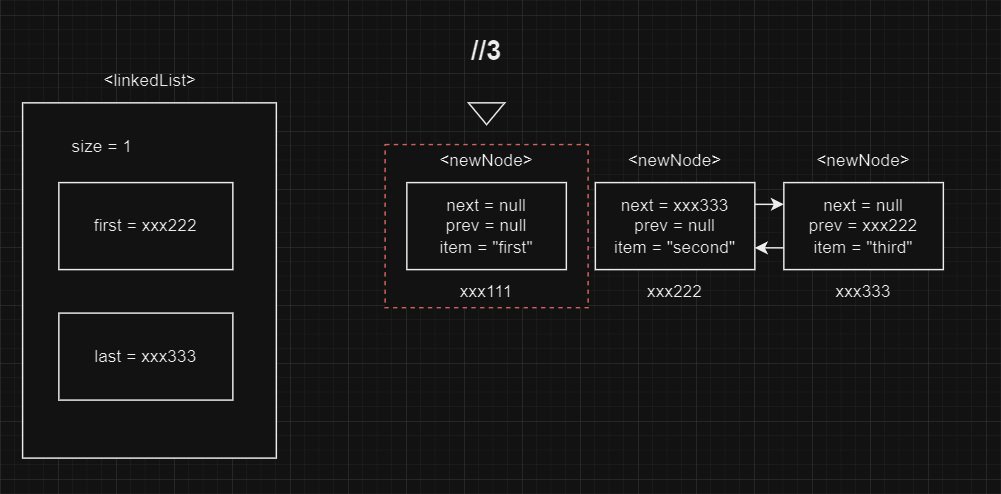
remove에서 값(item)이 일치하는 Node를 찾아 unlink에게 전달한다. 제시한 예시의 경우, prev = null, next = xxx222가 할당된다.
final E element = x.item; //1
final Node<E> next = x.next; //xxx222
final Node<E> prev = x.prev; //null
만약 prev=null 즉, 현재 노드가 제일 앞의 노드라면 linkedList의 first는 현재 노드의 next(다음 노드)가 된다.
if (prev == null) { //2
first = next;
} else {
prev.next = next;
x.prev = null;
}
근데 이해가 가지 않는 부분이 존재했다. first = next 이전에, next.prev를 null처리 하지 않는 이유는 뭘까?